CMU 15-445 Notes(2)
Lecture 9 Sorting & Aggregations
外部排序
查询时往往需要对元组进行排序:除了显式ODRER BY以外,还存在方便去重DISTINCT,聚合GROUP BY等优势。但是对DBMS而言,需要排序的数据量过大,以至于无法在内存中存下,于是产生了外部排序(external
sort)的需求。
external merge sort
归并排序的外部版本,设整个数据集被分成N个page:
- sort:在第一趟(pass)中,将每个page读入内存进行排序。
- merge:在之后的若干趟中,每一趟都将两个排好序的page集合(称为run)合成一个更大的run。这一过程需要使用3张buffer page(2输入+1输出),每当输出page满时就将其写入disk。
这就是2-way external merge sort,它需要运行$1 + log_2N $趟,每一趟都将整个数据集(N页)读出一次并写入一次,故产生了\(2N * (1 + \lceil log_2N \rceil)\)次磁盘IO。
更一般地,假设有B个buffer page可用,一次最多可以将B个page放在内存中比较,故sort步骤只会产生\(\lceil \frac{N}B \rceil\)个run(不需要留出一个page供输出,内存中可以原址排序,直接得到排好序的B个page)。而在merge过程中,需要预留一个buffer page,所以一次最多可以将B-1个run合成一个更大的run,故整个排序过程需要运行\(1+ \lceil log_{B-1}\frac{N}B\rceil\)趟,每一趟依然是将整个数据集读出并写入一次,故磁盘IO次数为\(2N*(1+ \lceil log_{B-1}\frac{N}B\rceil)\)。
基于聚集索引
如果有一个建立在排序key上的索引,而且它刚好是聚集索引(clustered index),可以直接遍历这个索引,依次从各key获取tuple。因为是聚集索引,取tuple的过程是顺序读写;对于非聚集索引,取tuple等于对disk进行随机读写,大大增加了读取次数。
聚合操作
为了执行SQL语句中的聚合操作,显然可以通过排序(内部或外部)数据集实现;然而在不要求ORDER BY的场景下,我们需要的仅仅是去重和计算聚合值,通过哈希实现相比排序更加轻量。
如果数据量过大,导致哈希表无法在内存中存下,我们也需要类似外部排序,使用外部哈希的方式做优化。否则哈希表始终只有一部分在内存中,通过某个指针访问其另一部分可能涉及到磁盘IO,在性能上无法接受。
external hashing
Partition,使用哈希函数h1将key映射到partition中去。partition是磁盘上的一个区域,由一页或者若干页组成,但是任何时刻一个partition中只会有一页在内存中,一旦写满了就换另一张空页进来。因此,外部哈希最多可以使用B-1个partition(1个用作输入),其中B为可用buffer page的数量。
ReHash,经过第一步,相同的key一定位于同一partition中。此时依次将每个partition读入内存中,使用哈希函数h2对其中的key做rehash(比如,
std::unordered_map),每个哈希表项的值存聚合后的结果(比如对AVG操作,value包含当前元素个数和元素总和),完成聚合操作。
ReHash中要求每个partition必须能完整放入内存,即大小不能超过B页,因此外部哈希能处理的最大哈希表大小是B*(B-1)页。所以为了对N页的表实现外部哈希,大约需要\(\sqrt N\)个buffer page。
Lecture 10 Join Algorithms
本课讨论的都是inner equijoin,即针对两张表中相同的key进行inner join;但是这些算法也适用于其他类型的join操作。
Join Output
在operator tree中,join运算符传递给上层的结果可分为两种:
- early materialization,将完整的两个元组合并,作为一个新元组向上传递。
- late materialization,在新元组中只包含待合并两个元组的join key部分,其他部分用Record ID代替。如果上层的运算符需要元组中的其他列,需要回到表里拿。列存储的数据库适合采用这种方式。
例子:
R(id, name)
| id | name |
|---|---|
| 123 | abc |
S(id, value, cdate)
| id | value | cdate |
|---|---|---|
| 123 | 1000 | 2021-01-01 |
| 123 | 2000 | 2022-02-02 |
则按照early materialization,输出给上层的结果是:
| R.id | R.name | S.id | S.value | S.cdate |
|---|---|---|---|---|
| 123 | abc | 123 | 1000 | 2021-01-01 |
| 123 | abc | 123 | 2000 | 2022-02-02 |
按照late materialization,输出给上层的结果是:
| R.id | R.RID | S.id | S.RID |
|---|---|---|---|
| 123 | xxx | 123 | yyy |
| 123 | xxx | 123 | zzz |
Join Algorithm
设两张表分别有M和N个page,m和n个元组。使用磁盘IO次数评估join算法的优劣,假设每页需要一次磁盘io。
Nested Loop Join
最朴素的想法是两层嵌套循环,对表1中的每个元组遍历表2中的每个元组,需要\(M+m*N\)次磁盘IO。注意到如果把规模较小的表作为外层循环(outer table),效果会好一点。
如果把迭代的最小单位变成page,即对于表1的每页遍历表2中的每页,再用两层循环遍历两页中的各元组,共套4层循环,可以把IO次数降到\(M+M*N\)次。
如果有B个buffer page可用,可以用B-2个存放outer table中的page(1个留作内层循环,1个留作输出使用),这样一来,IO次数可以降到\(M+\lceil \frac{M}{B-2} \rceil * N\)次。
如果整个outer table都能放进内存中(\(B-2 > M\)),IO次数为\(M+N\)次。
如果有inner table上有索引存在(不管是之前有的,还是为了做这次join新创建的),可以利用索引在inner table上查询而不用遍历整个i表,IO次数大约为\(M+m*logN\)。
Sort-Merge Join
先对两张表在join key上排序,然后维护两个指针,用类似归并排序的方式增长它们,找出相等的pair。outer table上的指针是单调递增的,但inner table并不是:如果outer table上有相同条目,inner table指针对每个相同条目都需要回退到其在inner table上第一次出现的位置。归并部分的复杂度大约是\(M+N\)(回退可认为发生了常数次),但在最坏情况下,两张表中所有条目在join key上的取值都相同(不太可能出现),归并退化为nester loop join,复杂度为\(M*N\)。
sort-merge join的复杂度为排序(可能是外部或内部)的复杂度+归并的复杂度。
sort-merge join适用于两张表(或其中的一张)本来就有序,或者输出要求join后的结果在join key上排好序的情形。
Hash Join
hash join的基本思路就是在join key上对表中元组做hash,避免在另一张表中全表搜索寻找当前元组的匹配项。
Basic Hash Join
- 基于outer table构建一张hash table,key是join key,value可以是record id或者整个元组(early/late materialization)。
- 基于inner table做探测,对每一个元组根据其join key计算hash值,和对应bucket中outer table的每一项比对,确认是否相等。
可以使用布隆过滤器优化:构建hash table时同时构建bloom filter,它足够小,可以放在cpu cache中作为fast path。探测时先查bloom filter,如果不存在就真的不存在,如果存在就需要查hash table确认是否为false positive。
Grace Hash Join
该方法主要解决hash table过大,以至于不能完全放入内存的问题。这种情况下读写hash table会构成对磁盘的随机访问,需要避免。
- 使用同样的哈希函数对outer table和inner table分别构建hash table。如果一个bucket过大以至于仍然不能完全放入内存,需要对其中元组继续使用不同的哈希函数做recursive partitioning,将其分成更小的partition,直到每个partition都能被完全放入内存为止。
- 两张表中join key相同的元组一定位于各自hash table中的对应partition中。因此,grace hash join的探测过程就是把两个hash table中的对应partition拿出来做nested loop join。recursive partitioning保证了每个partition都能完全放入内存。
Grace Hash Join的IO次数是\(3(M+N)\),其中:
- 构建hash table需要读出两张表中的每页,并将构建出的hash table写回磁盘,共\(2(M+N)\)次IO。
- 探测过程中会把每页读出来一次做比较,共\(M+N\)次IO。
讨论
除了上面提到sort-merge join适用的情形外,以及join key分布非常不均匀时(极端例子:两张表中join key只有一个取值,此时join算法退化为nested loop join),hash join是最通用的算法。
使用hash join时,如果能够预测输入表中元组的大致数目,可以构建容纳元素数目一定的静态哈希表,这可以降低建表和探测的开销,否则只能采用动态哈希。
为什么会存在不能预测输入表中元组数目的情形呢?对于多个表join的情形,先计算A join B的结果再和C join,此时A join B的元组数目就难以精确获得。连续join的次数越多,对中间结果元组数目的估计就越不准确。
对于inner equijoin以外的某些join需求,如要求两张表join key满足某一不等关系的inequality join,hash join不适用,因为hash对寻找两张表join key上的不等关系没有帮助。此时还是应该使用sort-merge join方式。
Lecture 11 Query Execution I
Processing Model
处理模型(processing model)定义了DBMS如何执行一个query plan。
Iterator Model
迭代模型Iterator Model又被称为volcano/pipeline model,它是几乎所有(行存储的)DBMS都支持的一种较为普遍的处理模型。
迭代模型的基本思想是每一个操作符都实现了自己的Next()函数,该函数每次被调用时会返回一个tuple,或是返回空指针,表示已经没有tuple可供返回了,就像一个迭代器一样。每个非叶子操作符的Next()实现都会循环调用其子操作符的Next()获取tuple,由该操作符处理后提供给上层;叶子操作符的Next()就是直接从表(或索引)中提取tuple。这样一来,tuple便从下到上沿着操作符树传递。
迭代模型之所以被称为pipeline model,是因为每个tuple被提取出来后会自下而上执行尽可能多的操作符,然后才会处理下一个tuple。这样做在每个tuple驻留内存的时间内做了尽可能多的处理工作,最小化磁盘IO。
一些操作符会阻塞流水线,直到它的子操作符向它传递了所有元组才能完成处理工作,并向上传递,比如join和order by。它们被称为pipeline
breaker。
迭代模型很适合进行output
control(即某个运算符获得足够的结果后就停止查询,比如LIMIT),因为元组本来就是一个个上来的。
Materialization Model
Materialization Model中,每个子操作符一次性接受输入,处理完后一次性向上输出。
对in-memory的DB而言,materialization Model更好:Iterator
Model通过流水线最小化磁盘IO的优势不存在了,同时大量调用Next()是一个负担。Disk-based
DB基本不用materialization Model。
Vectorization Model
向量模型就是两者的折中,每次Next()会返回一批而不是一个tuple。这样减少了Next()的调用次数,同时上层操作符可以利用CPU的SIMD指令加速处理。每“批”的大小是根据hardware和query的特点制定的,没有普适的选择。
Query Processing Direction
以上三种模型的方向都是自顶向下的,从操作符树的根节点开始,向下层节点“索要”数据。还有一种自底向上的query plan处理方向(少见),在数据传递过程中更好地控制对cache/寄存器的使用情况。
Access Method
Sequential Scan
没有索引可用的时候,不得不顺序扫描找到想要的元组。这很糟糕,但有一些优化手段:
- prefetching,见lecture 5
- buffer pool bypass,见lecture 5
- parallel,见lecture 12
- zone map,它是对每一页元组维护的额外元数据(如某属性的最大值),查询时先查zone map,如果能判断出该页元组不可能有满足条件的(比如最大值都比查询条件的下限小),直接跳过该页,否则再扫描该页的元组。
- late materialization,对列存储的DB,执行顺序扫描的操作符向上传tuples的一部分属性就行(比如record ID),要用的时候再拿其他属性,不用现在就拼好了再往上传。
Index Scan
选取合适的索引进行查找是一项困难的工作,这不仅和索引的属性、查询的属性有关,也和表中数据在这一属性上的分布、属性的值域等等因素有关。
现代DBMS往往支持同时在多个匹配的索引上查找,然后根据SQL中指定的谓词对查找结果(record ID的集合)做交/并操作,再在结果上执行剩余的运算。DBMS执行交运算的方式很多,bitmap、哈希表、布隆过滤器都能达到目的。
使用非聚集索引时,索引的顺序和数据实际存储的顺序不一定相同,可能导致随机访问。这种情况下DBMS只从索引中得到想要访问的tuple集合,再按照page ID对它们排序,再做顺序访问。
如果索引的区分度很低(极端情况:索引建在某个所有元组都取同一个值的属性上),DBMS宁愿不使用索引而直接顺序扫描。
Halloween Problem
对于顺序扫描和聚集索引扫描,写操作(如INSERT)可能会改变tuple的物理位置,从而导致cursor两次扫过同一元组。这一问题被称为Halloween
problem。
例子:对所有工资小于1100的人加薪100,在工资属性上的聚集索引上扫描。某个原工资为999的人被加成1099,它在索引上的物理位置往后移动了,再次扫到的时候如果不能区分出该元组已经被扫过,就会再次对他加薪100,导致错误。
Lecture 12 Query Execution II
并行查询可以提高查询的吞吐量,降低时延;对用户来讲能提高DBMS的可用性,降低部署成本和物理资源消耗。
并行式(parallel)和分布式(distributed)的数据库都通过使用更多的(计算或存储)资源来提高并行度,区别在于并行式数据库的资源之间物理距离很近(如多个CPU核心),它们之间的信息交互快速可靠;而分布式数据库使用的资源可能距离很远(如分布在世界各地的数据中心),它们之间的互联依赖公共网络,速度较慢且不十分可靠。
Process Model
process model定义了并行数据库如何支持并发请求。
process per worker
最基础,也是最早出现的模型是process per worker。应用请求被DBMS的dispatcher进程接收,它fork出一个新进程作为worker,之后应用直接与worker进程通信。
优势:
- 每个进程都有自己的context,一个worker进程一旦崩溃,不会影响整个DBMS。
劣势:
- 在该模型下,每个模型都是一个独立的进程,依赖OS做调度,DBMS缺乏控制。
- 同一个页(比如全局的数据结构)可能在多个worker进程的地址空间中都存在拷贝,造成浪费;共享内存可以缓解这个问题。
process pool
在process per worker模型基础上改进,不再对每个请求fork出worker执行,而是有一个进程池:dispatcher对每个请求指定进程池中的某个或某些进程作为worker执行查询请求。
优势:
- dispatcher对于规模较大的查询请求,可以指定多个进程作为worker来执行。而在process per worker模型中,dispatcher只管fork出一个worker,并把后续工作都交给它。如果这个worker发现查询请求规模较大,它必须自己再fork出新的进程分担工作,这就比直接从进程池中选进程来得慢。
劣势:
- 仍然依赖OS做进程调度。
- 每个query可能由不同的进程作为worker来执行,降低了CPU cache的局部性。
thread per worker
目前大部分DBMS使用的模型,整个DBMS只有一个进程,在其中使用线程作为一个worker。
优势:
- DBMS可以控制worker的调度。
- 线程上下文切换的开销比进程更低。
劣势:
- 一个worker crush可能导致整个进程崩溃。
Intra-Query parallelism
并行地处理查询请求分为请求间(inter-query)和请求内(intra-query)两类。前者在Lecture 15讨论,这里关心Intra-Query parallelism,它可以看作一个生产者/消费者模型,query plan中每个操作符向上层生产数据,同时消费下层操作符生产的数据。
Intra-Query parallelism可分为三个不同方式,它们不是互斥的,在一个query plan里可以同时使用。
Intra-Operator Parallelism (Horizontal)
操作符内并行化,就是把某个操作符待处理的数据集合划分成多个子集,然后由不同的worker在不同子集上并行地完成处理工作。这些工作可能是在操作各自的局部数据结构,也可能是写一个全局的数据结构(比如join操作需要对outer table中的元组构建一个hash table,扫描outer table的worker都是在对同一个hash table做插入,否则probe的时候要探测好几张hash table,性能不佳)。
为了实现操作符内并行化,DBMS在制定query
plan的时候会插入一种新的操作符,名为exchange。这个操作符是pipeline
breaker,只有它的子操作符全部向它输出完数据后才会继续向上传输数据。exchange被放置在并行化的操作符之上,它等待几个worker都完成其工作后,整合出一个单一的输出流向上传递数据。
上述提到的exchange其实属于gather类型,将多个输入流整合成一个输出流。exchange还有repartition类型(多个输入流重新分发成多个输出流)和distribute类型(单个输入流分发成多个输出流)。
Inter-Operator Parallelism (Vertical)
顾名思义,操作符间并行化是在操作符树的垂直方向上并行,即几个操作符被不同的worker并行执行,组成一条流水线。
Bushy Parallelism
Bushy Parallelism可以看作Inter-Operator
Parallelism的拓展,因为它使用了不同worker并行执行操作符树的不同部分;它也结合了Intra-Operator
Parallelism的exchange操作符,用exchange在不同worker之间传递中间结果。
I/O Parallelism
有时候执行query的瓶颈并不是计算资源,而是存储资源。以上针对计算资源的并行化方法无济于事,甚至因为破坏了顺序访问会让性能更差。此时I/O操作也需要进行并行化处理。
Multi-Disk Parallelism
Multi-Disk Parallelism是配置OS/硬件来将DBMS的文件存储到多个存储设备上,对DBMS透明。DBMS感知不到这一点,自然无法做并行化,此时的并行化是OS/硬件实现的(比如RAID)。
Database Partitioning
Database Partitioning是在DBMS层面进行配置,对数据库做分割,放到不同的存储设备上(分库分表),大致有两种方式:
- 垂直分割,把表的某些列分割出去,类似列存储。
- 水平分割,按照某个条件把表的部分元组分割出去。
Lecture 13 & 14 Query Planning & Optimization
SQL是声明式语言,生成并优化出高效的query plan是DBMS的责任。查询优化大致有以下两种思路:
- 使用静态/启发式的规则匹配query plan的一部分到已知的模式,将其优化成更高效的query plan。这种方式可能需要获得表的metadata以了解数据在表中是如何存储的,但是不需要访问数据本身。
- cost-based search,通过读出数据(因为最优的方案可能和数据在物理上的储存方式有关,比如是否压缩,是否排序等等),根据cost model预估不同query plan的执行代价来选择(被认为是)最低代价的方案。
Query Optimization Architecture
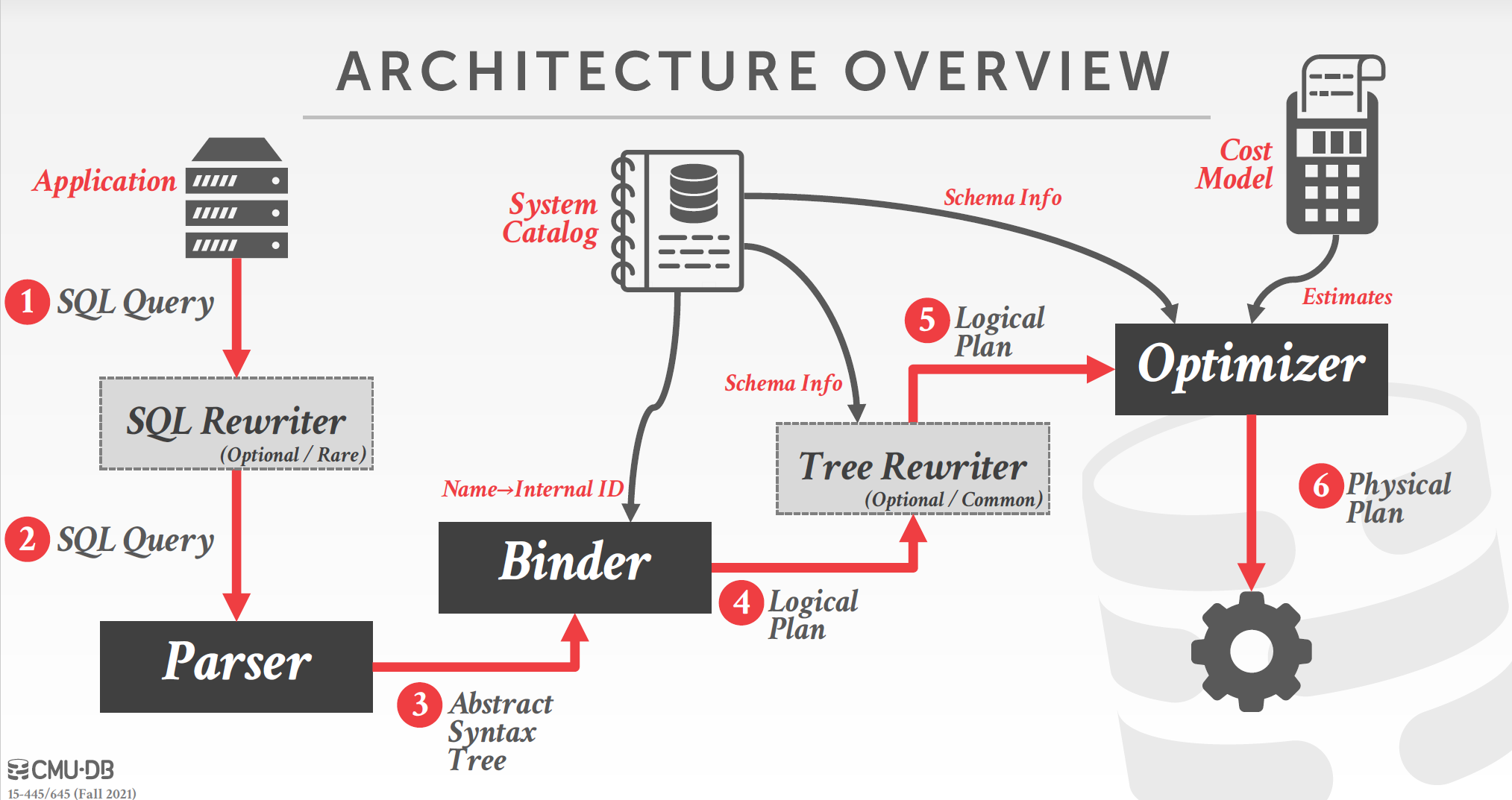
查询优化的大致架构如图所示:
- SQL Rewriter,在解析SQL之前使用预置的规则对其进行同义改写,添加注解等等,以提升性能。比如对于分布式数据库,SQL rewriter打上注解,告诉后续模块待查询的表在哪个节点上。这是一个可选模块。
- Parser,对SQL语句做语法分析,生成抽象语法树(AST)。
- Binder,把对于某个名称的引用替换成DBMS内部的某个标识符,以便后续使用。比如待查询的表名为"foo",binder查询数据库的catalog,找到表"foo"的ID,后续的步骤中使用该内部ID而非字符串"foo"来指代这个表;如果没有名为"foo"的表就抛异常告诉用户。Binder的输出是由语法树转化而来的logical plan,它大致和query对应的关系代数式等价,描述了完成查询需要做什么(查询/join哪些表),但并没有指定怎么完成这些步骤(使用哪种查询/join的方式),这些由physical plan指定。
- Tree Rewriter,logic plan已经是一个操作符树的形式了,Tree Rewriter的作用类似SQL Rewriter,使用一些静态规则和数据库catalog对操作符树进行局部改写以进行优化。这同样是一个可选模块,不过比SQL Rewriter更普遍存在。
- Optimizer,利用catalog和cost model对不同physical plan的估计值选择出最佳的physical plan。注意physical plan是每个操作符的执行细节(使用哪种join方法,使用哪个索引查找,等等),它和数据的物理储存方式有关,比如对一个有序的表可能sort-merge join比hash join更合适。
基于静态规则的查询优化
selection优化:
- 谓词下推,尽量早把filter的过滤操作做掉。
- 谓词重排序,先做筛选度高的谓词。
- 把一个多条件的谓词拆成几个,然后把能下推的下推。
projection优化:
- 投影下推,尽量早做投影操作让tuple变小。
- 插入额外的投影操作,把后续操作不需要的列去掉。
其他还有:
- 识别恒真/恒假的谓词条件
- 优化嵌套子循环:
- rewrite:重写,把嵌套的多层循环扁平化,合并成一个。
- decomposition:把嵌套的子循环拆成独立的query分别做优化。子query的结果会作为临时表供外层query使用,用完删掉。
基于cost估计的查询优化
DBMS有一个cost model对query plan的执行代价进行估计,这个代价涉及CPU、磁盘IO、内存和网络等多个方面。为了进行估计,DBMS会维护一些关于表、属性和索引的统计信息,它们会按照一定的策略被自动维护(比如表中超出某一阈值数目的元组被修改),也可以人工干预进行更新。
Selection Statistics
对每个表R,DBMS维护了tuple的数目\(N_R\),以及在每个属性上不同取值的数目\(V(A,R)\),用它们可以计算出每个属性上每个取值出现的次数\(SC(A,R) = \frac{N_R}{V(A,R)}\),称为选择基数(selection cardinality)。
选择基数可以用于估计谓词的selectivity,即该谓词能filter出的tuple比例,selectivity越小说明选择能力越强。很显然,对于形如A=constant的谓词,有\(sel=\frac{SC(A,R)}{N_R}\)。概率论的公式也可以用在\(sel\)的计算上,比如:
- \(sel(\neg P) = 1-sel(P)\)
- \(sel(P_1 \land P_2) = sel(P_1) * sel(P_2)\)
- \(sel(P_1 \lor P_2) = sel(P_1) + sel(P_2) - sel(P_1) * sel(P_2)\)
以上的结论基于一些假设,对于真实数据这些假设很可能并不成立,所以cost model估计的代价不是完全准确的,它们是:
Uniform Data,属性上每个值均匀分布。
Independent Predicates,谓词之间相互独立。
Inclusion Principle,对inner table的每个join key,outer table都存在join key与之相等的条目(即假设应用不会join两个基本没有联系的表)。
为了应对假设不成立的情况,DBMS也可能有一些其他的手段来估计选择基数:
- 直方图,统计某属性上每个取值的出现次数。为了节省空间,还可以把相近的取值合并到一起进行统计。
- 采样,对表中数据进行采样,对样本进行统计来代表整体。
Plan Enumeration
有了估计query plan时间的方法后,DBMS就要在某一时限内枚举query plan,找出最好的那个。对于只涉及单表的查询,问题比较简单,主要就是找access method(顺序扫描、走索引等等),往往使用一个启发式策略就能解决问题。对于涉及多表的查询,join的顺序导致可选方案数指数级增加,这时候可能需要动态规划之类的方式找最佳方案。