Stanford CS144 Notes(1)
Chapter 1 Intro
1-3 The IP service model
IP: unreliable, best effort, connectionless datagrams, why?
- 简单更可靠
- 在端设备而不是网络上实现复杂功能(不同于电话网络:端设备简单而网络复杂)
- 允许上层根据需要实现功能,比如视频聊天对可靠要求不高(UDP)
- 对链路层不做任何假设,要求低
然而IP也在easy和functional中做权衡,因此还具有以下特点:
- 防止packet在网络中无限循环(hop-count(TTL) in IP header)
- 对太大的packet分片传输
- header checksum,防止packet被传输到错误的位置(?为什么不是保证packet的完整性)
- 可以更新版本,IPv4和IPv6
- header中允许加入新option。但这要求整个网络的路由器都支持新选项,某种程度上违背了simple的原则,实际上很少用
1-5 Packet switching principle
packet: 一段自含(self-contained)的数据,所谓自含,即packet本身包含了足以将它送到目的地的元信息。
packet switching: 对每个到达的packet独立地选择outgoing link。If the link is free, send it. Else holding the packet for later.
- 源路由,packet包含一路上每个hop地址。理论上可行,但是不安全,不用。
- packet只包含目的地址,一路上的路由器根据目的地址做转发决定。
packet switching使路由器不需要维护流的状态,实现更简单,也让link更容易被复用。
1-8 byte order
网络领域的协议都使用大端序,需要注意network order与host order之间的转换问题。
1-11 Address Resolution Protocol
设备与局域网内另一设备(如网关)通信时需要知道其MAC地址,它会在链路层广播ARP请求,包含该设备的IP地址。该设备接收到请求后将自己的MAC地址单播/广播给请求者,请求者将IP与MAC地址的映射关系存在本地cache中。
- 只有被请求的设备会回复ARP请求,局域网中其他设备即使知道该映射关系也不会回复请求者。这样做使得只有设备A自己才能更新其他主机关于A的映射关系缓存,其好处是一旦某个设备离开网络,等到所有设备的cache中关于它的信息都过期了,它的状态就从网络中被清除了。
- 但是,ARP请求包含请求者的IP和MAC地址,它被广播出去后,接收到请求的各设备会更新本地关于请求者的IP-MAC映射缓存。
- 按照ARP的specification,response应该被单播给请求者。但是现在的实现更多是把response广播出去,让全局域网的设备都可以更新关于自己(被请求者)的IP-MAC映射缓存。
ARP还有一种被称为gratuitous ARP(免费/无理由ARP?)的用法,在这种情境下,设备发出ARP请求,但dest IP是自己的IP,即试图查询自己的MAC地址。这样做可以:
- 检查局域网中是否有IP冲突:如果请求者收到了对gratuitous ARP的回复,证明存在IP冲突。
- 让网络中的其他主机收到该广播,强制更新自己在局域网中的其他主机那里的IP-MAC映射缓存。
Chapter 2 Transport(intro)
2-1 TCP service model
唯一标识一个TCP连接的是一个五元组:(源IP,目的IP,源端口号,目的端口号,协议名(TCP)),其中协议名就是IP header里表明上层(传输层)协议是TCP的字段。如果没有协议名,仅靠两个端口号和两个IP无法确定这是个TCP连接,也可能是其他的传输层协议。
2-2 UDP service model
UDP像是在IP层上做了一个简单包装的传输层协议,在IP的基础上提供了多路复用,即将packet根据端口号转交给对应的应用。
应用使用UDP不一定是不关注可靠性,也可能是不想依赖TCP的可靠传输机制而自己实现。
UDP header里有一个可选的checksum,只当网络层是IPv4时可用。这个checksum计算时不仅包含UDP报文的内容,也包含网络层IP header的部分内容(源和目的IP,协议号等)。这种行为某种程度上破坏了层间隔离,其目的是让checksum能够校验出报文被传输到了错误的主机的情形(即目的IP不对)。TCP的checksum也会包含部分IP header的内容一起参与计算。
2-3 ICMP service model
ICMP主要用作网络层的error reporting,但它的报文又是放在IP packet里传输的,因此它可以看作介于网络层和传输层之间的协议。
ICMP的报文内容包括其回复的IP packet的头部和内容前8字节,这样源主机可以判断这个ICMP报文是对哪个IP packet的回复。
ICMP报文直接封装在IP packet里,所以它和UDP一样是不可靠的。
ping和traceroute是两个直接使用ICMP的例子。ping使用了ICMP协议中的echo request和echo response,traceroute发出TTL从1开始逐渐递增(用于获取跳数),且UDP目的端口号不合法的IP packet,通过router回应的TTL超时ICMP报文和目的主机回应的“端口不可达”ICMP报文得到他们的IP。
2-5 Error Detection
error dection都是通过在报文中附加冗余信息完成的,可以放在头部或尾部。
三种error dection模式:
- checksum,最快最简单,检错能力差,只能确保检出1位错。TCP和IP使用。
- Cyclic Redundancy Code(CRC),计算比checksum复杂(但硬件实现的计算还是比较快),检错能力更强。以太网使用。
- Message Authentication Code(MAC),不同于CRC的设计目的是对抗传输过程中自然产生的错误,MAC是密码学方法,对抗人为的恶意攻击。MAC不保证检出任何错误,只是以相当大的概率检出错误。TLS使用。
在error detection中,“确保检出错误”是非常强的保证,实际上能做到以相当大的概率检出错误已经能满足使用了。
关于MAC“不保证检出任何错误”,我的理解是MAC从数学上不保证两个相近(比如只差1位)的串加密后的密文不一样(尽管大概率如此),不像checksum和CRC能保证某一范围内的错误一定会导致校验值的变化。
2-7 ~ 2-9 Flow Control
两种流量控制:停等(stop and wait)和滑动窗口(sli
ding window),前者可看作发送窗口大小SWS和接收窗口大小RWS都为1的滑动窗口。
滑动窗口中,一次失败导致整个窗口都需要重传称为"go back N",只需要重传失败的packet称为"selective repeat(SR)",这是由RWS的大小决定的,使用"go back N"策略的RWS为1,使用“selective repeat”策略时的RWS=SWS。
序列号空间的大小不能小于SWS和RWS之和,否则无法区分ACK是确认新报文还是重传的报文。使用"go back N"策略需要\(SWS+1\)个序列号;使用“selective repeat”策略需要\(2*SWS\)个序列号;使用停等策略需要2个序列号。
2-11 TCP Setup and Teardown
TCP连接的建立和拆除除一般流程外,还有同步建立(simultaneous open)和同步拆除(simultaneous close)的特殊情况。
- simultaneous open中,两台主机几乎同时向对方发送SYN。发完SYN后处于SYN_SENT状态下的主机接收到对方发来的SYN后会直接进入SYN_RCVD状态并回复SYN/ACK,收到对方发来的SYN/ACK后连接建立,因此发生了4次握手。注意在正常流程中,SYN_SENT是active opener的状态,而SYN_RCVD是passive opener的状态。
- simultaneous close中,两台主机几乎同时向对方发送FIN。发完FIN后处于FIN_WAIT1状态下的主机接收到对方发来的FIN后会进入CLOSING状态并回复ACK,收到对方发来的ACK后进入TIME_WAIT状态,仍然是4次挥手。注意在正常流程中没有CLOSING这个状态,它是simultaneous close特有的。
Chapter 3 Packet Switching
3-2 Principles What is packet switching
因特网不使用电路交换的原因有:
- 计算机之间的通信大多具有突发性(bursty),比如通过ssh打字时,单词与单词之间会有停顿;打开网页时可能请求一系列资源,但浏览时没有网络请求,等等。对于大量的突发请求,使用专用信道无法让通信链路得到充分利用。
- 计算机通信时的速率差异很大。服务器可能以MB级的速率传输视频,用户可能以一秒一个字符的速率打字。使用固定速率的信道不合适,带来浪费。
- 健壮性不高,一旦专用信道中某一设备崩溃,整个信道就无法使用。但对于包交换网络,某台路由器发生故障,依然可以使用其他路径把包发到目的地。
3-3 End-to-end Delay
传播时延(propagation delay):\(t_p = \frac{l}{c}\),其中\(l\)为链路长度,\(c\)为传播速度(一般和光速在一个数量级)。传播时延和链路的速率无关。
传输时延(transmission/packetization delay):\(t_t=\frac{p}{r}\),其中\(p\)为包大小,\(r\)为链路传输速率。传输时延是将一个包完全推到链路上的时间。
网络上两台主机间的端到端时延(end-to-end delay)可以表示为\(t=\sum\limits_i (\frac{p}{r}+\frac{l}{c} + Q_i(t))\),\(i\)是路径上的每台路由器,多出来的\(Q_i(t)\)项是排队时延,它是造成端到端时延不稳定的主要因素。
一台路由器必须完整接收到一个包才能开始向下一跳发送它,因此减小包的大小可以降低端到端时延。
3-6 Queueing Model Properties
排队论:
Burstiness increases delay;Determinism minimizes delay
利特尔法则(Little’s Raw):稳定系统中,长期的平均顾客人数(L),等于长期的有效抵达率(λ),乘以顾客在这个系统中平均的等待时间(W),即\(L=\lambda W\)
M/M/1 排队模型:
- 前提:
- 顾客到达时间是泊松过程(等价于:到达时间间隔满足指数分布),记到达速率为\(\lambda\)
- 服务时间满足指数分布,记服务速率为\(\mu\)
- 只有一个服务窗口
- 隐含了\(\lambda \lt \mu\),否则队列无限增长
- 结论:
- 顾客平均排队时间\(d=\frac1{\mu - \lambda}\)
- 平均队列长度\(L=\frac{\lambda}{\mu - \lambda}\)(利特尔法则)
- 前提:
3-7 & 3-8 Switching and Forwarding
TCAM
CAM(content-addressable memory)可以看作RAM的反面,不是给定地址取数据,而是向CAM给定要查询的数据,CAM返回数据所在的地址。 CAM可以并行地对所有存储单元进行比较查找操作,从而在一个时钟周期内返回结果。
TCAM(Ternary CAM)是三进制版的CAM,除了0和1外还允许储存'X'匹配任意值,从而实现最长前缀匹配,可用于路由器中对路由表的查询。
Input and Output Queueing
ref:Lecture 12: Input and output queueing
路由器必须维护一个缓存队列,来应对packet的输入速率大于输出速率的情形。缓存队列的实现有几种方式:
- 只有一大块共享内存,N个输入端口和N个输出端口都从这里读写packet。最坏情况下2N个端口都在读写同一块内存,也即内存的速率必须是端口链路速率的2N倍。
- output queue,在每个输出端口处维护一个队列。最坏情况下N个输入端口进来的packet全都要去同一个输出端口,加上输出端口自己,内存速率必须是端口链路速率的(N+1)倍。
- input queue,在每个输入端口处维护一个队列,该队列单位时间内只要完成1次入队和1次出队,内存速率只需要达到端口链路速率的2倍。
然而input queue会带来head-of-line blocking的问题:假如输入端口1,2,3的头部都有发往输出端口4的packet,端口4随机选择端口1向它发包。此时即使端口2的队列中全是发往输出端口5的packet,它们也必须等队列头部那个发往端口4的包被随机选择并发走之后才能被发出。
解决这一问题的方式是virtual output queue,每个input queue由N个VOQ组成,每个VOQ对应一个输出端口。input queue把发往特定输出端口的packet存在对应的VOQ里,这样输出端口就能看到每个输入端口那里要发到自己这里来的packet了。
3-9 Rate guarantees
上面所说的路由器“队列”都是FIFO队列,它区分不了不同优先级的packet(控制报文>数据报文,视频流量>email流量,给钱多的用户>给钱少的用户,等等)。
于是我们引入了机制,为不同链接的传输速率做出保证:
- strict priorities,简单说就是队列分不同优先级,只有在没有更高优先级的队列需要服务时,才会服务低优先级队列。这样做高优先级的队列感知不到低优先级队列的存在(低影响不了高),但是低优先级队列可能会被饿死。
- rate guarantee,不同优先级的队列权重不同,按照权重服务不同队列,guarantee就是权重\(w_i\)的队列能分到\(\frac{w_i}{\sum\limits_jw_j }\)比例的带宽。
rate guarantee实现起来看似很简单,只有不停按顺序扫所有队列,扫到权重\(w_i\)的队列就读出\(w_i\)位即可。但考虑到路由器处理的是packet,只有攒到一个完整的包才能发出去,不能几位几位地发,因此还得把读了一半的包存起来;如果按packet为单位读,不同packet的长度差距很大,这样做又会破坏权重模型对带宽分配的保证。所以有一种被称为WFQ(Weighted Fair Queueing)的策略。
WFQ的思想就是按packet为单位去读队列,一次就把一个packet读完,而不是按位去读。为了保证带宽分配比例,WFQ的调度器会选择SN(sequence number)最小的包去读。
SN可以看作该packet在应有的带宽保证下(即该队列有一个恒定的带宽),预计被读完的时间。(有点像CFS里的vruntime)
- 记队列\(i\)中第\(k\)个包在\(S_{i,k}\)时间开始被读出,在\(F_{i,k}\)时间被读完。队列权重\(w_i\)可以看作单位时间读取的大小,则有\(F_{i,k} = S_{i,k} + \frac{L_k}{w_i}\),其中\(L_k\)为包大小。
- 如果队列带宽有恒定保证,显然有\(S_{i,k} = max(F_{i,k-1},t_{now})\)(服务完前一个包立刻服务下一个包,除非它还没到)。
由以上的式子可以推出每个包的\(F_{i,k}\),它就是SN。
不难看出,优先级越高的队列\(F_{i,k}\)越小,因此越早得到服务;所有队列优先级相等的情况下,较小的包更容易得到优先服务。
关于WFQ可以参考这里。
3-10 Delay guarantees
end-to-end delay中不可控的是排队时延,但假如路径中每台路由器都使用了WFQ策略,即有了速率保证\(R_i\),那排队时延也有了上限\(\frac{B_i}{R_i}\),其中\(B_i\)是缓冲区的大小。只要源端的瞬时发送速率不要太高而把缓冲区打爆,就可以提供一个端到端时延的上限保证。
控制瞬时发送速率可以使用令牌桶(token bucket/leacky bucket)。
Chapter 4 Congestion Control
4-1 & 4-2 Congestion Control - Basics
Max-min fairness
考虑网络中对不同数据流分配带宽,它们各自对带宽大小的请求不同。如果无法在不降低其他流速率的情况下提升某一流的速率,这种分配就达到了max-min fairness(不考虑所有请求加起来都没有链路总速率大的trivial情况)。这个问题不局限于带宽分配,可以一般化成资源分配的问题。
直观来看,max-min fairness认为所有请求者应该平均(或按指定的权重)分配资源(配额),如果某个请求者的请求小于配额,可以满足它的请求,并把配额中多出来的部分平均(或按指定的权重)分配给其他“贪婪”(即请求大于配额)的请求者。
Max-min这个名字是因为该算法使得:请求未被完全满足的请求者中获得份额的最小值最大。(maximizes the minimum share of a source whose demand is not fully satisfied)
拥塞控制的分类
按照网络层是否为拥塞控制提供帮助,可以分为end-to-end和network based两类。
在需要网络层支持的拥塞控制中,路由器可以提供网络中拥塞状况的反馈信息,它可以直接反馈给发送方,也可以放在packet里传输到接收方,再由接收方反馈给发送方。ECN(Explicit Congestion Notification)就是一个这样的协议。
端到端的拥塞控制不需要网络层支持,端系统通过观察网络层的行为(丢包,时延)推断出发生了拥塞。IP层不提供拥塞控制的网络层支持,所以TCP的拥塞控制就是实现在端上的。
TCP的拥塞控制复用了流量控制里滑动窗口的机制,实际发送窗口的大小取接收窗口(rwnd,用于流量控制,由接收方控制)和拥塞窗口(cwnd,用于拥塞控制,由发送方控制)的最小值。
4-3 & 4-4 AIMD
AIMD(Additive-Increase Multiplicative-Decrease)算法控制拥塞窗口的变化:
- 每当一个包被成功传输(收到ACK),令\(W=W+\frac1W\)。因此一整个窗口被成功传输会使得\(W=W+1\)。
- 每当一个包丢失,令\(W=\frac{W}2\)。
AIMD在只有一条连接的single flow模型,和真实网络的multi flow模型下性质有所不同:
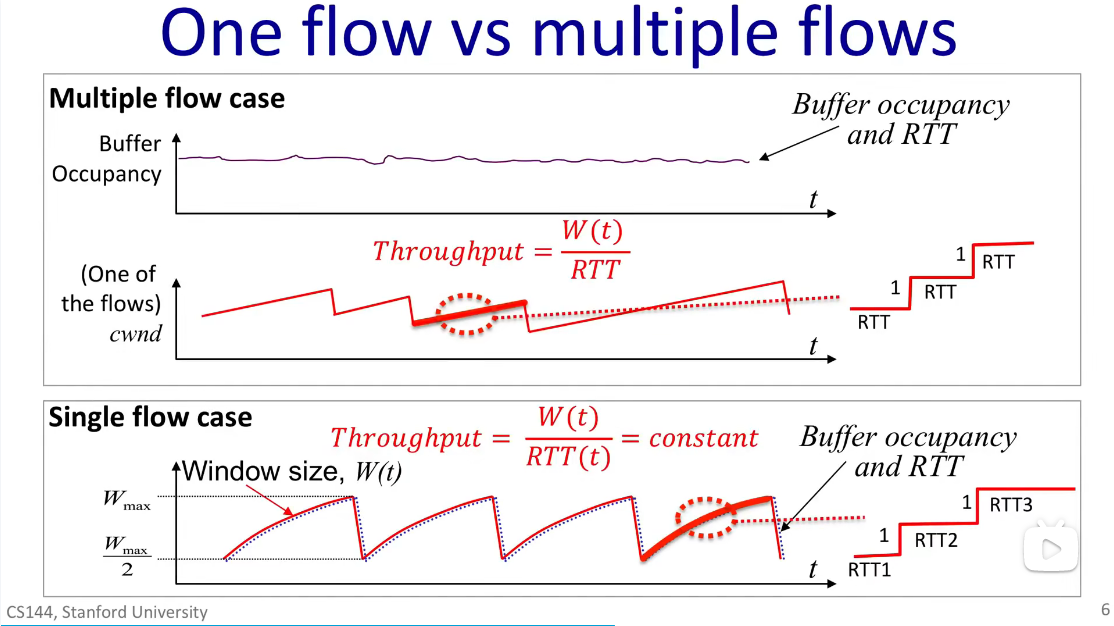
single flow
这种情况下,随着W变大,缓冲区中的包数目变多,最终装满缓冲区导致丢包,使得AIMD将窗口大小减半,缓冲区积压的包开始变少,如此循环。RTT和缓冲区中包的数目密切相关,缓冲区越满,排队时延会导致RTT越大。
对于single flow的情形,式\(R=\frac{W(t)}{RTT(t)}\)中的W和RTT同步变化,吞吐量R近似一个常数。
multi flow
在真实网络的multi flow情况下,一个缓冲区里有来自成千上万条链接的数据包,某一条链接窗口大小W的变动对整体而言微不足道,不会导致缓冲区中包的数目大幅变化,因此RTT可以看作一个常数。
对于multi flow的情形,根据式\(R=\frac{W(t)}{RTT}\)可以得出吞吐量与窗口大小成正比变化的结论。
此外,从图1中还能看出:single flow情况下加性增的过程是一个上凸函数,而multi flow时加性增是一条直线。这还是RTT是否为常数导致的,图1右边的锯齿就是“直线”的局部放大图。
AIMD下网络吞吐量计算
AIMD下W的变化可以看作一个周期函数,从\(\frac{W_{max}}2\)线性增长到\(W_{max}\),再骤降回到\(\frac{W_{max}}2\),这个周期的长度是\(\frac{W_{max}}2*RTT\)(因为每个RTT窗口大小+1)。因此一个周期发送的数据包数目是: \[ A=0.75W_{max}*\frac{W_{max}}2*RTT = \frac{3}{8}W_{max}^2 \] 一个周期只丢一个包(导致窗口大小减半的那个),因此丢包率\(L=\frac1A\)。
由上可以计算吞吐率R(单位时间发出的数据包数目): \[ R=\frac{A}{T}=\frac{\frac{3}{8}W_{max}^2}{\frac{W_{max}}2*RTT}=\frac34*\frac{W_{max}}{RTT}=\sqrt{\frac32} * \frac1{RTT*\sqrt L} \] 从上式可以看出,AIMD下吞吐率R对丢包率\(L\)敏感,对往返时延RTT更敏感。
4-5 ~ 4-8 TCP Congestion Control
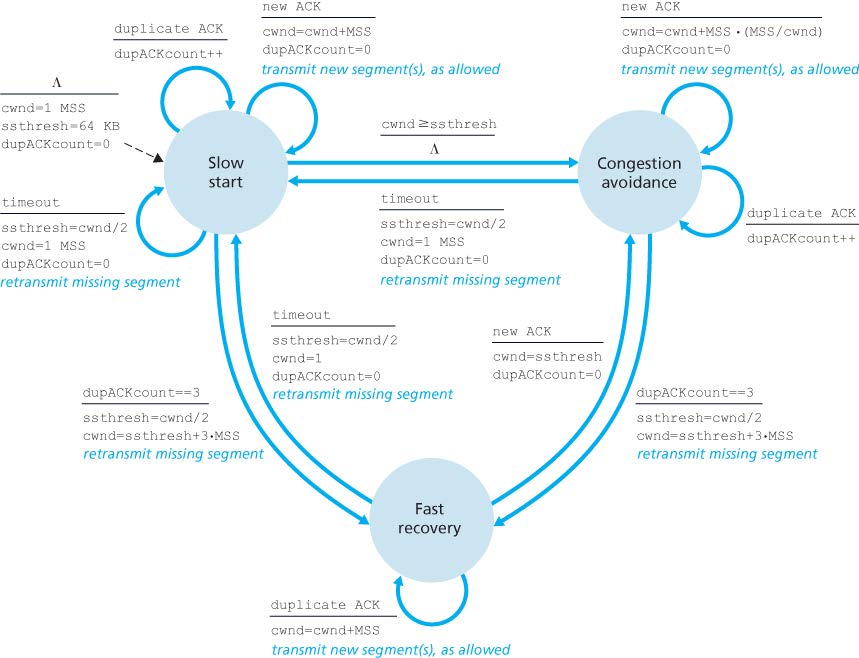
TCP Tahoe
Slow start:对每个ACK,将cwnd增加一个MSS的大小。因此每个RTT内cwnd翻倍,是指数增加。
Congestion avoidance:对每个ACK,将cwnd增加\(MSS*\frac{MSS}{cwnd}\)大小,由于一个RTT发送了\(\frac{cwnd}{MSS}\)个包,每个RTT内cwnd加一,是线性增加。
当cwnd超过阈值ssthresh时,TCP从慢启动转入拥塞避免;当出现丢包/重复ACK时,TCP回到慢启动状态,并将cwnd置为1,ssthresh减半。
直观来看,慢启动用于探测网络的容量,拥塞避免在接近容量时缓慢进行探测。
Fast Retransmit
如果一个包超时了,TCP认为发生了丢包并进行重传。其实可以通过收到重复的ACK来判断发生了丢包并重传,不需要等到超时。在TCP Tahoe中,收到3个重复的ACK视同于超时,也会导致回到慢启动状态。
TCP Reno
TCP Reno在Tahoe的基础上引入了快速恢复(Fast revocery)状态。Tahoe认为重复ACK等于超时,但Reno认为重复ACK是比超时稍弱一点的证明网络存在拥塞的证据(因为一个ACK就说明网络中少了一个包,它已经进了目的路由器的buffer),因此会在收到3个重复ACK时进入快速恢复状态:将ssthresh减半,但cwnd不被置为1,而是减半。
快速恢复这个名字指的是TCP连接不一定要经过慢启动的指数增加过程就能回到拥塞避免状态。在快速恢复状态下,发生超时会导致TCP回到慢启动状态,收到正确的ACK会使得TCP回到拥塞避免状态,同时将cwnd设置为ssthresh的值。
Congestion Window Inflation
在快速恢复状态下,收到重复的ACK会让cwnd增加一个MSS,这一行为称为Congestion Window Inflation。
为什么会有这样的设计呢?重复ACK意味着丢的包之后的所有包都需要重传,而重传的包的ACK至少需要一个RTT才能到达。如果这个过程中cwnd保持不变,意味着TCP连接在一个RTT内无法发送任何包(因为窗口的头部已经被固定住了)。而一个ACK(不管是否重复)就说明网络中少了一个包,收到重复ACK时(包括引起快速恢复状态的3个重复ACK),我们应该向网络中发送/重传一个新包。在窗口头部被固定住的情况下,这只能通过暂时增大cwnd来实现。
例子:设\(cwnd_{old}=16\),包1丢失,进入快速恢复状态,且\(cwnd_{new}=8\)。此时上一个cwnd的16个包会导致15个重复ACK,因此\(cwnd_{new}\)可以增长到23,允许我们在重传包1的ACK到来之前这一个RTT的时间里,在重传剩余15个包的情况下再发送7个新包。重传包1的ACK到来后,窗口已经可以移动了,cwnd回缩到8,就像Tahoe里从慢启动回到拥塞控制时的状态一样。
PS:TCP的重传机制有点像Go Back N(累积确认)和Selective Repeat(会缓存失序包)的混合。
完整的TCP Reno状态机如图:
RTT Estimation
设置包的超时间隔来进行重传,需要对RTT进行估计。RTT是经常变化的值,可以通过指数加权移动平均(EWMA)从采样值维护估计值。EWMA的特点就是越新的样本在加权平均时的权值越大。 \[ EstimatedRTT = (1- \alpha)EstimatedRTT + \alpha SampleRTT \] 只有平均值是不够的,它不能体现RTT取值的分布情况,需要有一个值衡量采样值一般会偏离估计值的程度: \[ DevRTT = (1-\beta)DevRTT + \beta \left| SampleRTT-EstimatedRTT\right| \] 我们的目的是保证超时间隔大于RTT,但又不能大得太多,因此这个差值就可以用DevRTT来定义。 \[ TimeoutInterval = EstimatedRTT + 4 \cdot DevRTT \] 超时间隔加倍:大部分TCP实现中,在超时重传后会把超时间隔加倍,直到收到ACK时才恢复到根据上式计算超时间隔。这是防止网络拥塞时大量包被重传,反过来又加重了拥塞情况。
AIMD的公平性
TCP中拥塞控制算法的公平性可以用下图来说明:加性增阶段两条链接每过一个RTT,cwnd都增加一个RSS,因此沿斜率=1的直线移动;乘性减阶段两条链接的cwnd等比缩减。因此最后两条链接的带宽占用量会收敛到中间的公平位置。
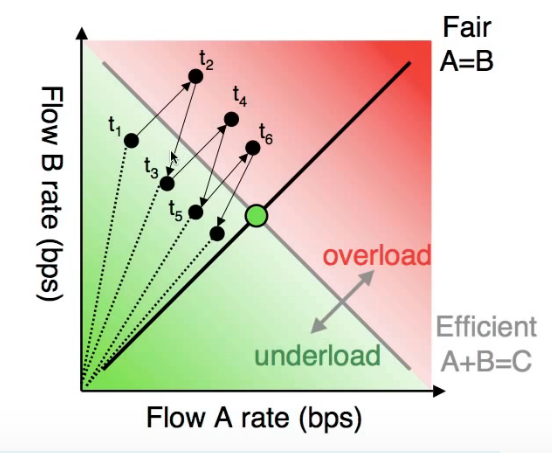
上述讨论基于所有链接的MSS和RTT相同,事实上如果两条链接共享同一个瓶颈链路,RTT小的那个可以更快让自己的cwnd涨上去,导致不公平。