CMU 15-445 Notes(3)
Lecture 15 Concurrency Control Theory
Transaction是对数据库系统中读写操作的更高一层抽象,代表了“一个单位”的数据库操作\(^{[1]}\)。
Transaction可以表示为对数据库中某些对象的一系列读写操作,由一个BEGIN标记txn的开始,ABORT或者COMMIT标记txn的结束。
Transaction应该具有ACID(Atomicity,Consistency,Isolation, Duration)的特性。
Atomicity
事务应该是原子的,即要么事务中的全部操作全部完成,要么全部未完成。
达成Atomicity的方式:
- Logging(主流),DBMS记录所有的操作,可以用来在从crash恢复后撤销完成了一半的事务。
- Shadow Paging,对事务需要修改的数据页进行copy,事务在copy上进行修改,提交时再用copy替换掉原来的页。
Consistency
Consistency描述数据库在逻辑上的正确性。如果数据库在执行事务之前是一致的,且执行完事务后也是一致的,则该事务具有一致性。
Isolation
Isolation指所有事务的执行不受其他事务的影响,就好像它们独自在DBMS中被执行一样。让所有事务顺序执行显然可以达到Isolation,但出于性能考虑,DBMS往往允许事务并行执行,并采用Concurrency Control确保Isolation。Concurrency Control Protocol的任务就是生成与顺序执行等价的执行序列(事务有很多,顺序执行可能有很多种,与其中任何一种等价即可)。
Concurrency Control Protocol可分为乐观和悲观两类:
- Pessimistic,假设事务并行执行一定会冲突,于是采取措施(如加锁)不让冲突发生。
- Optimistic,假设事务并行执行中发生的冲突不多,于是在事务COMMIT后处理可能发生的冲突(如回滚事务)。
冲突(Conflict)定义为:从属于不同事务的操作作用于同一个对象,且其中至少一个为写操作。冲突的类型有:
- Read-Write Conflicts (“Unrepeatable Reads”):先读后写,事务1读对象后,事务2修改该对象,事务1再次读该对象发现结果与第一次读到的不同,称为不可重复读。
- Write-Read Conflicts (“Dirty Reads”):先写后读,事务1写对象后,事务2读该对象,之后事务1被撤销,但事务1的修改被事务2读到了,称为脏读。
- Write-Write conflict (“Lost Updates”):事务1写对象后,事务2再次写该对象,导致事务1的写入被覆盖。
等价性
前面提到Concurrency Control Protocol要能够生成与顺序执行“等价”的执行序列,所谓“等价”有三种定义:
- final state equivalent,两种执行序列是final state equivalent的,当且仅当对数据库任意的初始状态,两种序列能够使数据库转移到相同的最终状态。
- view equivalent,两种执行序列是view equivalent的,当且仅当两种序列中所有“读取”操作读到数据的来源(即来自于某个事务中某次“写入”操作,或是来自于初始状态)一样,且每个数据库对象的最后一次写入操作所处的事务也一样。 说人话:两种执行序列中,每个事务执行过程中“看到”的数据库状态是一样的。
- conflict equivalent,两种执行序列是conflict equivalent的,当且仅当两种序列中每对冲突(Conflict)操作的先后顺序都是一样的。
如果一个执行序列\(S_1\)与顺序执行序列\(S_2\){final state, view, conflict} equivalent,则称\(S_1\)具备{final state, view, conflict} serializability。
以上三种定义按照从弱到强排序,serializability程度越强,牺牲的并发程度就越多,并发性能就越差。
要保证Consistency,达到view serializability就足够了。但是检查一个执行序列是否为view serializability是一个NP-complete问题,所以实际的DBMS中绝大部分都是以牺牲一部分并发程度为代价,采用conflict serializability。Conflict serializability可以通过dependency graph来检查。
这部分可以参照引文[1]的详细描述。
Durability
所有提交成功的事务都必须被DBMS持久化存储,即crash之后它们不会消失。
Lecture 16 Two-Phase Locking
DBMS中会使用锁(lock)来在不事先知道事务具体读写对象过程的情况下,保证事务的(conflict) serializability。锁保护的是数据库对象,它们由数据库中一个中心化的lock manager所管理。按照锁的排他性可以分为:
- Shared Lock(S-Lock),允许多个事务读同一个对象。如果一个事务拿了某对象的S-Lock,其他事务也可以拿到该S-Lock。
- eXclusive Lock(X-Lock),允许事务写对象。如果一个事务拿了某对象X-Lock,其他事务都拿不到该对象上的S-Lock或X-Lock。
为了保证conflict serializability,DBMS需要在事务的读写序列中插入一系列lock和unlock操作,在读/写对象时必须先拿到对应的锁。事务提出的lock请求可能会被lock manager同意或拒绝,如果被拒绝,它必须等待其他事务释放该锁。
2PL
Two-Phase Locking(2PL)是一种基于锁的悲观concurrency control protocol。它的思想是:一旦某事务释放了它所持有的任何一个锁,它就不能再获得任何锁。因此每个事务的执行过程都可以分为growing和shrinking两个阶段,其持锁数量分别单调不减和单调不增。
2PL可以保证conflict serializability,即保证所有冲突操作的顺序。反证法证明:
- 假设某遵循2PL的执行序列不满足conflict serializability,则dependency graph中必存在环。
- 对环中每条边\(T_i \rightarrow T_j\),\(T_i\)和\(T_j\)中必存在一对冲突动作,并且\(T_i\)中的动作先执行,\(T_j\)中的动作后执行。
- 假设这对冲突动作操作的对象是\(O\),一定是\(T_i\)一定先释放\(O\)上的锁,\(T_j\)后获取\(O\)上的锁。
- 由2PL的性质可以得出:一定是\(T_i\)先进入了shrinking阶段,\(T_j\)才完成了growing阶段。
- 上述结论对环中每条边都成立,即若环中存在边\(T_j \rightarrow T_k\),可推出\(T_j\)先进入了shrinking阶段,\(T_k\)才完成了growing阶段。于是传递得到:一定是\(T_i\)先进入了shrinking阶段,\(T_k\)才完成了growing阶段。
- 结论传递完整个环,得出结论:一定是\(T_i\)先进入了shrinking阶段,\(T_i\)才完成了growing阶段。这显然是荒谬的,故假设不成立,满足2PL的执行序列一定满足conflict serializability。
Rigorous 2PL
2PL会导致cascading aborts:
- 事务1写入了对象\(O\)后,事务2读了对象\(O\)。
- 如果此时事务1被abort,则事务2不得不也被终止。因为事务2读到的对象\(O\)的值来自一个被abort的事务。
事务2被终止可能会让更多的事务被迫终止,导致雪崩,所以称为cascading aborts。这本质是一个dirty read的问题。
解决方法是以牺牲更多并发程度为代价,采用更严格的2PL策略:Strong Strict 2PL(又名Rigorous 2PL),它保证事务所持有的所有锁都在事务被commit时一起释放。这样一来其他事务不可能读到脏值。
Deadlock
2PL不能避免死锁,因为两个事务可能以相反的顺序拿某两个同样对象上的锁。DBMS可以采取死锁检测和死锁避免的方式解决死锁问题。
死锁检测(deadlock detection):DBMS维护一张等待图(wait-for graph),如果\(T_i\)在等待\(T_j\)持有的锁,则存在一条从\(T_i\)指向\(T_j\)的边。一旦等待图中出现环,就说明出现了死锁。DBMS需要选中一个事务,并将其全部或部分回滚,破坏等待图中的环。
死锁避免(deadlock prevention):DBMS保证拿锁的顺序,防止死锁的发生。当一个事务请求另一个事务持有的锁时,DBMS可能会abort其中一个事务来避免死锁。
- Wait-Die ("Old Waits for Young"):设\(T_1\)比\(T_2\)先开始,如果\(T_1\)请求了\(T_2\)持有的锁,\(T_1\)进入等待;如果\(T_2\)请求了\(T_1\)持有的锁,\(T_2\)被终止。这是非抢占的策略,因为已经持锁的事务不会被终止。
- Wound-Wait ("Young Waits for Old"):设\(T_1\)比\(T_2\)先开始,如果\(T_1\)请求了\(T_2\)持有的锁,\(T_2\)被终止;如果\(T_2\)请求了\(T_1\)持有的锁,\(T_2\)进入等待。这是抢占的策略,因为已经持锁的事务可能被抢锁,而自己被终止。
Wait-Die和Wound-Wait两种方法本质相同,都是控制了事务间等待的顺序(老等少/少等老),如出现与等待顺序相反的锁请求,会导致年轻的事务被终止。PS:被终止的事务如果重启,应该沿用之前的时间戳。否则它每次重启都变得更年轻,可能被新来的事务一直欺负。
Lock Granularity
如果锁的粒度太小,我们需要拿很多次锁才能完成操作(比如扫描一亿个tuple的表,需要拿一亿个元组上的锁)。可以把不同对象的锁组织成一个树状结构(比如table锁的后代是tuple锁,tuple锁的后代是attr锁),拿了上层的锁就等于隐式地拿了其后代锁。
然而这样一来,上锁操作就变得更加复杂了——不仅需要检查当前锁,还需要检查其所有祖先和所有后代,以此判断新加的锁是否会与其祖先和后代中任何一个已经被持有的锁冲突。于是引入了意向锁(Intention lock)的概念:
- IS,若事务对某节点上了IS锁,说明它会显式地对某个子节点上S锁。
- IX,若事务对某节点上了IX锁,说明它会显式地对某个子节点上X锁。
- SIX,相当于S锁和IX锁的结合,该节点被同时上了S锁和IX锁。虽然两个事务不能分别持有S锁和IX锁,但是对一个事务而言,既持有S锁也持有IX锁也不会带来正确性问题,所以引入了SIX锁的概念。
意向锁的相容性矩阵(即两个事务分别试图持有某对象的锁的相容性情况):
| S | X | IS | IX | SIX | |
|---|---|---|---|---|---|
| S | Y | N | Y | N | N |
| X | N | N | N | N | N |
| IS | Y | N | Y | Y | Y |
| IX | N | N | Y | Y | N |
| SIX | N | N | Y | N | N |
解释:
- 节点持S锁,其所有子节点都不能上X锁,所以与X,IX,SIX不相容。
- 节点持X锁,其所有子节点不能上任何锁,所以与所有锁不相容。
- 节点持IS锁,其某个子节点会上S锁,因此与X不相容。但是可以与IS,IX,SIX相容,因为其持X锁的子节点不一定就是持S锁的子节点。
- 节点持IX锁,其某个子节点会上X锁,因此与S,X,SIX不相容。但是可以和IS,IX相容,因为其持X锁的子节点不一定就是持S锁的子节点。
- 节点持SIX锁,取S和IX相容情况的交集,即只与IS锁相容。
Lecture 17 Timestamp Ordering
Timestamp ordering(T/O)是一种乐观的concurrency protocol,它使用时间戳来保证事务的serializability order。
每个事务会被指定一个单调递增的Timestamp(TS),如果\(TS(T_i) < TS(T_j)\),DBMS必须保证执行序列与一个\(T_i\)在\(T_j\)之前执行的顺序执行序列等价。TS可能是当前时间,也可能是一个逻辑计数器,也可能是它们的混合。
Basic Timestamp Ordering(BASIC T/O)
BASIC T/O为每个数据库对象\(X\)维护两个值:\(RTS(X)\)和\(WTS(X)\),分别记录最后一个读/写此对象的事务的时间戳。事务在读写每个对象前都要检查是否违反了Timestamp order,如果违反则终止并重启当前事务。
读操作:
- 如果\(TS(T_i) \lt RTS(X)\),说明违反了Timestamp order(\(T_i\)试图读一个未来才会被写入的值),此时\(T_i\)被abort,并以新的时间戳重新被执行。
- 否则,读操作可以成功执行,更新\(RTS(X) = max(RTS(X), TS(T_i))\)。
写操作:
- 如果\(TS(T_i) \lt RTS(X)\) 或者 \(TS(T_i) \lt WTS(X)\),说明违反了Timestamp order(\(T_i\)没有在被使用之前写入它应该写入的值),此时\(T_i\)被abort,并以新的时间戳重新被执行。
- 否则,写操作可以成功执行,更新\(WTS(X) = TS(T_i)\)。
优化(Thomas write rule):
- 写操作时如果满足\(TS(T_i) \lt WTS(X)\)且不满足\(TS(T_i) \lt RTS(X)\),可以不终止并重启\(T_i\),而只是忽略这次写操作(因为这次写操作被覆盖了,并且没有其他事务读这个被覆写的数据)。
如果不使用Thomas write rule,BASIC T/O生成的执行序列是conflict serializable的。它的缺点有:
- 执行时间较长的事务因为与频繁到来的新事务冲突而被反复重启,造成饥饿。
- 分配时间戳在高并发情景下成为瓶颈。
Optimistic Concurrency Control (OCC)
OCC在事务之间冲突较少的情况下效果很好(如所有事务都是读操作,或每个事务都操作数据库的一个划分,相互没有交集)。
在OCC下,DBMS为每个事务创建私有空间,读操作会把对象copy到私有空间中,写操作会操作私有空间中的对象。事务提交时,DBMS检查当前事务的提交是否与其他事务冲突,如果不冲突才会把更改update到数据库中。
OCC把每个事务分为3个阶段:
- Read Phase,(在私有空间中)进行事务中的读写操作。之所以叫Read Phase,是因为数据库在这个阶段只是被读取。
- Validation Phase,验证待提交的当前事务是否与其他事务冲突。
- Write Phase,将事务的修改从私有空间同步到数据库中。
OCC的缺点有:
- validation阶段需要读别人的私有空间,看看别人都干了啥。这在物理上(latch层面)会导致对某些数据结构的高争用。
- 在私有空间和数据库之间的拷贝动作会带来开销。
- 事务被终止的代价会很大。因为事务只可能在Validation阶段被终止,此时事务的读写操作已经完成了,它们全白做了。
- 分配时间戳在高并发情景下成为瓶颈。
隔离级别
幻读(Phantom Read):插入/删除操作导致范围查询语句(如MAX)作用于旧的元组集合,导致错误。
解决幻读问题的方法有:
- Re-Execute Scan,对于事务中的范围查询操作,在事务commit之前重新扫描一下,看结果是不是发生了变化。想法很trivial,性能不佳。
- 谓词锁(Predicate Locking),对SELECT语句中的WHERE子句上共享锁(S),对UPDATE/INSERT/DELETE等语句种的WHERE子句上排他锁(X),不让范围查询涉及到的元组集合被修改(即插入/删除元组)。
- 索引锁(Index Locking),对范围查询中谓词涉及到的属性所在的索引页上锁(如果这个属性上没索引,只能锁table了),防止相关元组被插入/删除。
SQL-92标准定义了4种隔离级别:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ-UNCOMMITTED | √ | √ | √ |
| READ-COMMITTED | X | √ | √ |
| REPEATABLE READS | X | X | √ |
| SERIALIZABLE | X | X | X |
之前讨论的2PL,T/O等concurrency protocol都是为了实现SERIALIZABLE,即事务间的完全隔离。隔离级别降低以后,事务间不再是完全独立的,而是会互相影响,但同时性能也得到提高。
实现各隔离级别的方式:
- SERIALIZABLE:strict 2PL(或T/O concurrency protocol) + Index Lock
- REPEATABLE READS:strict 2PL(或T/O concurrency protocol)
- READ-COMMITTED:(not strict) 2PL,且S锁会被立刻释放。这就导致可能出现unrepeatable read。
- READ-UNCOMMITTED:(not strict) 2PL,去掉S锁。这就导致可能出现dirty read。
Lecture 18 Multi-Version Concurrency Control
MVCC是一种概念,涉及到数据库涉及与实现的多个方面,而不仅仅是一种并发控制协议。MVCC的基本思想是对数据库中同一个逻辑对象维护多个物理版本,写操作会创建新版本的对象,而读操作会读到事务开始时存在的最新版本的对象。
MVCC可以让reader和writer之间不相互阻塞,因为每个reader看到的都是数据库在某一时刻的snapshot,该时刻之后的修改对该reader不可见。此外MVCC可以很自然地支持time-travel query,即在某一时刻的数据库snapshot中进行query。
MVCC的重要design decision有:
- concurrency control protocol(就是之前lecture的2PL,T/O等等)
- version storage
- garbage collection
- index management
Version Storage
version storage决定数据库如何管理一个对象的不同版本。DBMS使用version chain以链表的形式将对象的不同版本串联起来。
- append-only storage,一张表中所有tuple的不同版本全都混杂在一起,写入的时候就在表后面追加,然后update链表指针。
- time-travel storage,表中只维护每个tuple的最新版本,并且每个tuple有一个指针指向其历史版本的链表。
- delta storage,与time-travel storage类似,不过历史版本不是完整的tuple,而是每次修改变化的部分。这样写操作更快,但是读历史版本更慢,因为需要逐步重建历史tuple。
链表可以从最新指向最老(N2O),也可以反过来(O2N),但对于delta storage显然只能N2O,不然没法重建历史版本。
Garbage Collection
DBMS需要清理无用的历史版本。
- tuple-level,即定期检查并清理无用的tuple。分为:
- Background:单独的清理线程遍历table,并结合当前active事务的timestamp判断哪些历史版本可以被回收。DBMS可以将上一次垃圾回收以来被修改过的元组所在的页标记为脏页,以避免遍历所有页中的元组。
- Cooperative:每个工作线程通过version chain访问相应tuple时就顺便清理不用的历史版本。只适用于O2N的version chain。
- transaction-level,每个事务维护自己读写导致的历史版本,并传给garbage collector,不需要逐tuple检查。
Index Management
MVCC会产生很多不同版本的对象,因此version chain的变动是比较频繁的。
主键索引(primary index)直接指向每个tuple的version chain的头部(即物理地址),如果version chain发生变化,就需要更新主键索引指向的指针。
非主键索引(secondary index)就有不同设计思路了:
- 可以和primary index一样直接指向物理地址(查一次,version chain更新时需要update所有secondary index)
- 也可以指向一个逻辑id,如primary key,再根据该逻辑id去查一次主键索引得到想要的tuple(多查一次,但是update方便,只要更新主键索引中的指针)。
Lecture 19 Logging Schemes
Recovery算法的目标是保证数据库crush之后的一致性、事务原子性和持久性,它由两个部分组成:
- 正常事务处理逻辑中做出的操作,确保DBMS在crush之后可恢复。
- DBMS crush之后做出的操作,将数据库恢复到一个一致的状态,这包括撤销未提交事务的影响(UNDO)和确保已提交事务正确落盘(REDO)。
数据库Failure可分为:
- Transaction Failure,某事务执行失败,可能因为:
- 逻辑错误,比如试图插入不符合表约束的tuple。
- 状态错误,比如产生死锁,DBMS不得不杀死一个事务来解决死锁。
- System Failure,包括软件方面(DBMS有bug)和硬件方面(插头被拔了)。在讨论Recovery时,我们假设断电会导致内存中数据全部丢失,而磁盘中已落盘的数据不会被破坏。
- Storage Media Failure,如硬盘坏了导致数据丢失,这就不属于数据库能恢复的failure了。
Buffer Pool Policies
DBMS在管理Buffer Pool和disk之间数据同步时,可以针对Runtime(正常运行)和Recovery时的性能,采取不同的trade off。
steal:是否允许事务将尚未提交的数据持久化到disk中?
force:事务是否必须在COMMIT之前将其所有修改落盘?
采用No-steal + force策略时,Runtime性能最差,Recovery性能最好。事实上,这种策略下根本不需要recovery,因为未提交的事务不可能持久化其修改,已提交的事务一定已经将修改落盘。
作为代价,该策略:
- 每次提交事务前都要写磁盘,影响性能。
- 每个事务修改的规模受到内存缓冲区限制,因为不允许将尚未提交的数据落盘。
- 如果两个事务修改了同一磁盘页的不同位置,DBMS不能一次将该页落盘(因为事务提交总有先后),而必须把修改分两次先后落盘,造成写放大。
Shadow paging
shadow paging是一种No-steal + force策略的实现。它把数据库维护master和shadow两个副本,分别代表已经提交的事务(已经落盘)的数据和未提交事务修改的数据。所有未提交事务都在shadow中做修改,事务提交时会让shadow成为新的master。
实现中,不需要将整个数据库拷贝成两份,只要对有修改的页维护两个副本即可(类似COW)。shadow page是在内存中的,但它们可能被buffer pool manager隐式交换到磁盘上,好处是事务修改规模可以突破缓冲区上限,坏处是事务执行过程中就可能发生flush影响性能,且容易造成磁盘碎片。另外,shadow paging不能处理两个以上写事务并行的情况。
Write-Ahead Logging
WAL是应用最广泛的Recovery方法,它是指DBMS在把buffer pool中修改过的页刷回之前,必须先记一个log,并把log刷到磁盘。
log被记录在内存中,并且不同事务的log不会分开,是交错记录的。事务提交时把该事务涉及到的log页落盘,且一旦日志落盘,就认为事务COMMIT已经成功。一种优化是事务提交时等待一会,等到几个事务都要提交时再一起写入它们的log,减少写盘次数。
WAL中一般使用Steal + No-force的方式,最大化运行时性能,但是在recovery时就需要根据log重放操作。
日志中一般记录:事务BEGIN,事务COMMIT,每个操作的事务ID,对象ID,操作之前的值(用于Undo),操作之后的值(用于Redo)。
Logging Scheme
根据日志记录的内容可以分为:
- physical
logging,字节粒度,对每个操作,记录所有修改处的变化(类似
git diff)。比如某页某偏移处从A值变为B值。 - logical logging,只是在high level记录每个操作,比如把执行的SQL语句记录下来。
logical logging占用的空间更小,但是恢复时需要重建每个动作的影响,恢复更慢;此外对于并行事务无能为力,因为无法还原当时的并发调度情况。
一种折衷是两者的混合Physiological Logging,它类似physical logging,但是不会具体到偏移量,只是用到page number和slot number索引。这就使得DBMS碎片整理时(比如将数据页中的空隙补上,导致偏移量变化)不需要修改每个log中的偏移量。
Checkpoint
DBMS会在日志里插入一些checkpoint,该点之前提交的事务已经被持久化,crash恢复只需要从最近的checkpoint开始即可,不用从头开始遍历整个WAL。
Lecture 20 ARIES Database Recovery
Algorithms for Recovery and Isolation Exploiting Semantics (ARIES)是IBM提出的Recovery算法,主要的思想有:
- write ahead logging,且buffer pool策略是steal + no-force。
- Redo时根据log将数据库恢复到crash之前的状态。
- Undo时做的操作也需要记录,防止crash之后又chash导致撤销时的操作被重复执行。
ARIES使用的WAL记录有一个额外字段:全局唯一且单调递增的Log Sequence Number(LSN),作为每条日志的ID。同时DBMS需要维护一些关于LSN的额外元数据:
| Name | Where | Definition |
|---|---|---|
| flushedLSN | memory | 最后一个被flush到磁盘上的LSN |
| pageLSN | each page | 最后一个操作该页数据的LSN |
| recLSN | each page | 该页上一次被flush到磁盘之后,第一个操作该页数据的LSN |
| lastLSN | each transaction | 该事务中最后一条日志的LSN |
| MasterRecord | disk | 最后一个checkpoint的LSN |
任何一页被持久化到磁盘之前,必须保证涉及该页的log也被持久化,即\(pageLSN_i < flushedLSN\)。
Normal Execution
在讨论事务的正常执行流程时,本课程基于以下的假设:
- 所有日志不超出一页大小,因此落盘是原子操作。
- tuple是single-version的,并使用strict 2PL并发策略。
- buffer pool策略是steal + no-force。
COMMIT流程:
- 在WAL中记录COMMIT日志。
- 将COMMIT日志及之前的日志落盘。
- 将事务已成功提交的信息返回给用户。
- 在WAL中记录TXN-END日志。(不需要立刻落盘)
COMMIT日志只代表数据库向用户返回了成功提交,其内部还维护着该事务的元信息和一些数据结构;TXN-END日志代表在数据库内部,对该事务的处理已经完成,后续的日志中不会再出现和该事务相关的信息。
ABORT时是把之前的修改回退,也是对数据库的修改,因此也需要记日志,称为Compensation Log Records(CLR)。CLR和正常日志一样,但是多出一个字段undoNextLSN,表示下一个需要回退的操作的LSN。同时,每条日志也会维护previous LSN指针,指向属于该事务的上一条记录,相当于维护了一个反向链表。这样ABORT时就不需要每次遍历日志寻找下一个需要回退的操作(即属于该事务的上一个操作),顺着反向链表走就行。
ABORT流程:
- 在WAL中记录ABORT日志,并将事务已经ABORT的信息返回给用户。
- 反向遍历当前事务的日志,撤销每个操作并记录CLR日志。
- 完成后,在WAL中记录TXN-END日志。
注意ABORT日志不需要立刻落盘,且通知用户ABORT也不需要等待所有回滚操作做完。就算ABORT到一半crash了,下次重启后DBMS发现这个事务没做完,它会(在Undo中)重新开始回滚。因此,在ARIES中,可以把ABORT操作看作Undo作用于一个事务的特例。
Checkpoint
传统的checkpoint需要DBMS停止处理当前已经开始的事务,停止接收新事务,然后再将所有脏页落盘并记录checkpoint。
ARIES使用fuzzing checkpoint的策略,允许DBMS在记录checkpoint时,其他事务正常执行。引入两个数据结构:
- Active Transaction Table(ATT),记录当前时间点所有活跃(即:未TXN-END)的事务。每个表项包括txnID,txnStatus和lastLSN(该事务最后一条日志的LSN)。
- Dirty Page Table(DPT),记录当前时间点所有脏页,每个条目包括脏页的ID和recLSN值。
首先,checkpoint不再是一个点,而是由CHECKPOINT-BEGIN和CHECKPOINT-END标示出的一段区间。CHECKPOINT-BEGIN处根据当前数据库的状态得出ATT和DPT,然后开始将所有非脏页落盘(与此同时,事务正常进行)。完成flush后记录CHECKPOINT-END日志,并在CHECKPOINT-END日志中带上ATT和DPT。MasterRecord指针指向最后一个CHECKPOINT-BEGIN处。
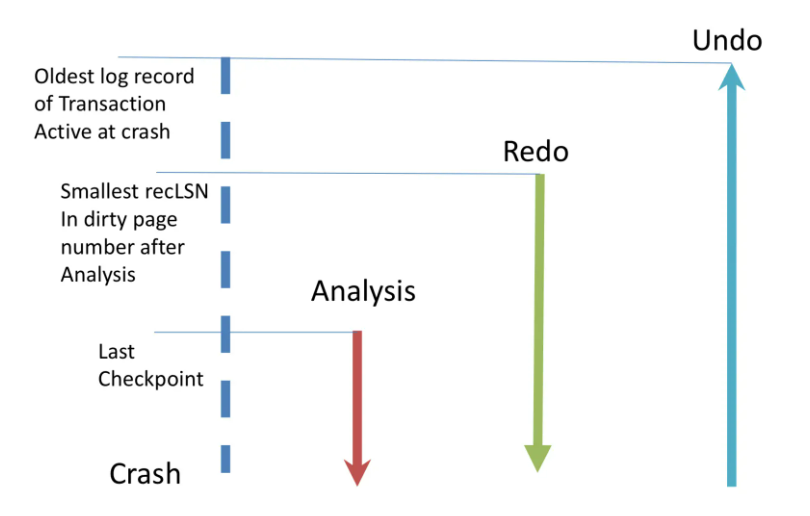
Recovery
ARIES恢复过程由3个部分组成:
- Analysis,根据WAL得出在crash发生的时间点,尚未TXN-END事务的状态(ATT)和尚未flush的脏页(DPT)。
- Redo,从日志中某个位置开始,重放每个操作。
- Undo,回退crash发生时没有提交的操作。
Analysis
从最后一个CHECKPOINT-BEGIN处向后遍历WAL,并从CHECKPOINT-END处读到ATT和DPT:
- 遇到一个TXN-END,将该事务从ATT中删除。
- 遇到一个COMMIT,将该事务的状态改为C(Commited)。
- 遇到其他类型的记录,将该记录所在事务加入ATT,状态为U(Undo candidate,待Undo)。
- 如果遇到update记录,且涉及到的页不在DPT中,还要将涉及到的页加入DPT,并将recLSN设为该记录的LSN。
完成Analysis过程后,DBMS拿到了crash发生时的事务状态和脏页情况。
Redo
Redo的目的是恢复出crash时刻所有脏页上的修改情况。
从DPT中所有脏页recLSN的最小值对应的记录开始,重新执行所有update记录(包括CLR)并更新相应页面上的pageLSN,除非:
- 该操作影响的页不在DPT中。或者,
- 该操作影响的页在DPT中,但该页的recLSN大于该操作的LSN。(说明脏页上的修改不包括该操作)或者,
- 该操作影响的页在磁盘上的pageLSN大于该操作的LSN。(说明该操作的修改已经被持久化到磁盘上了)
Undo
针对所有状态为U的事务,按照LSN从大到小的顺序回退它们所做的操作,并记录CLR。
- TO-UNDO集合初始包括所有状态为U的事务的lastLSN。
- 每轮循环中,选择并移除TO-UNDO集合中最大的LSN。如果是CLR记录,将其undoNextLSN(如果非空)加入集合;如果是update记录,将其previous LSN(如果非空)加入集合,并写入对应的CLR记录。
- 循环步骤2,直到TO-UNDO集合为空为止。
Undo可以进行lazy优化:不是立刻进行每条记录的回退操作,而是将需要回退的页记下来,后续其他事务访问这些页的时候才根据日志逐步回退。这样做的好处是数据库从crash恢复后可以很快接收并处理新事务,而不需要等待所有Undo完成。
三个阶段的操作涉及到的日志范围如图: