/* * highest_zoneidx represents highest usable zone index of * the allocation request. Due to the nature of the zone, * memory on lower zone than the highest_zoneidx will be * protected by lowmem_reserve[highest_zoneidx]. * * highest_zoneidx is also used by reclaim/compaction to limit * the target zone since higher zone than this index cannot be * usable for this allocation request. */ // 允许的最大zone序号,本次分配不能从序号更高的zone中分配内存 enumzone_typehighest_zoneidx; // 是否考虑脏页平衡 bool spread_dirty_pages; };
if (cpusets_enabled()) { *alloc_gfp |= __GFP_HARDWALL; /* * When we are in the interrupt context, it is irrelevant * to the current task context. It means that any node ok. */ if (in_task() && !ac->nodemask) ac->nodemask = &cpuset_current_mems_allowed; else *alloc_flags |= ALLOC_CPUSET; }
/* Dirty zone balancing only done in the fast path */ ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE);
/* * The preferred zone is used for statistics but crucially it is * also used as the starting point for the zonelist iterator. It * may get reset for allocations that ignore memory policies. */ ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask);
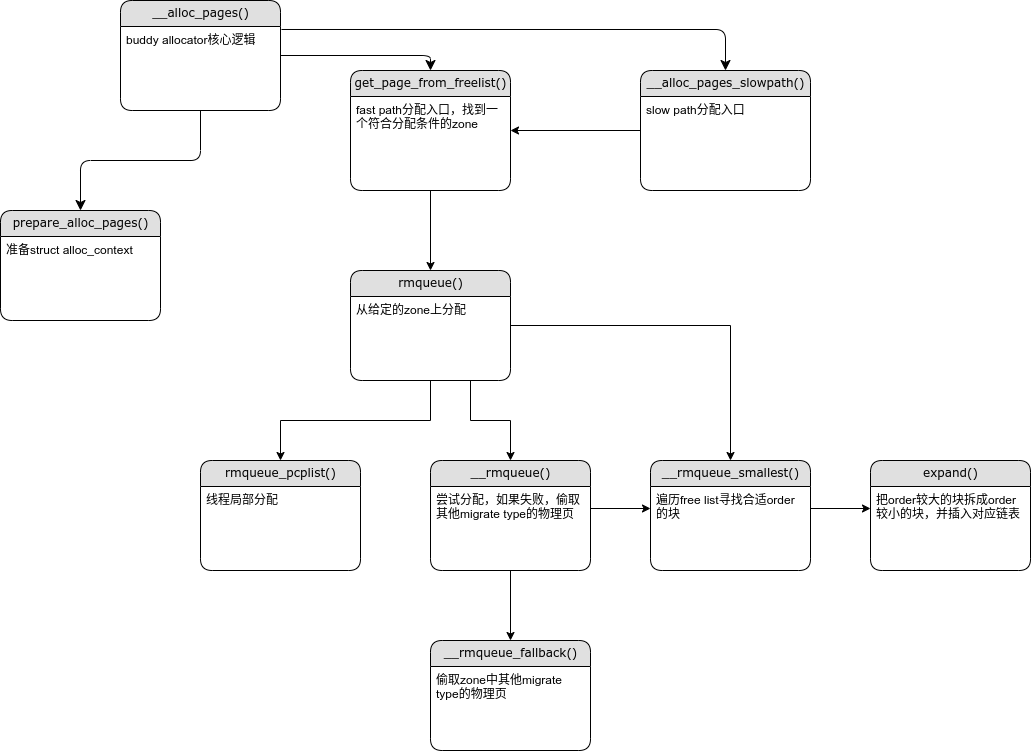
/* * Allocate a page from the given zone. Use pcplists for order-0 allocations. */ staticinline struct page *rmqueue(struct zone *preferred_zone, struct zone *zone, unsignedint order, gfp_t gfp_flags, unsignedint alloc_flags, int migratetype) { unsignedlong flags; structpage *page;
if (likely(pcp_allowed_order(order))) { /* * MIGRATE_MOVABLE pcplist could have the pages on CMA area and * we need to skip it when CMA area isn't allowed. */ if (!IS_ENABLED(CONFIG_CMA) || alloc_flags & ALLOC_CMA || migratetype != MIGRATE_MOVABLE) { page = rmqueue_pcplist(preferred_zone, zone, order, gfp_flags, migratetype, alloc_flags); goto out; } }
/* * We most definitely don't want callers attempting to * allocate greater than order-1 page units with __GFP_NOFAIL. */ WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1)); spin_lock_irqsave(&zone->lock, flags);
do { page = NULL; /* * order-0 request can reach here when the pcplist is skipped * due to non-CMA allocation context. HIGHATOMIC area is * reserved for high-order atomic allocation, so order-0 * request should skip it. */ if (order > 0 && alloc_flags & ALLOC_HARDER) { page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC); if (page) trace_mm_page_alloc_zone_locked(page, order, migratetype); } if (!page) page = __rmqueue(zone, order, migratetype, alloc_flags); } while (page && check_new_pages(page, order)); if (!page) goto failed;
/* * Go through the free lists for the given migratetype and remove * the smallest available page from the freelists */ static __always_inline structpage *__rmqueue_smallest(structzone *zone, unsignedintorder, intmigratetype) { unsignedint current_order; structfree_area *area; structpage *page;
/* Find a page of the appropriate size in the preferred list */ for (current_order = order; current_order < MAX_ORDER; ++current_order) { area = &(zone->free_area[current_order]); page = get_page_from_free_area(area, migratetype); if (!page) continue; del_page_from_free_list(page, zone, current_order); expand(zone, page, order, current_order, migratetype); set_pcppage_migratetype(page, migratetype); return page; }