System Software for Persistent Memory
Intro
在引言部分,本文讨论了系统软件管理PM的三种不同方式,它们是:
- 完全摒弃文件系统,由操作系统的Virtual Memory Manager像管理内存那样管理PM。
- 为PM实现块设备接口,用传统文件系统加以抽象。
- 实现没有block layer的PM专用文件系统。
本文提出的PMFS选择了第三种方式,基于下列几个理由:
- 实现文件系统接口可以支持一系列传统应用。
- PM文件系统可以实现得很轻量,抛弃传统的block layer,不需要以块粒度将数据在持久化存储设备和DRAM直接拷贝。
- 可以通过MMIO,让应用用访问内存的语义访问PM。然而传统文件系统的MMIO会把被访问的页从持久化存储设备拷贝到DRAM,而实现PM专有文件系统可以避免这些拷贝,直接将PM映射到用户地址空间。
System Architecure
New Hardware Primitive
本文的贡献之一是提出了一种硬件原语pm_wbarrier(pcommit),来保证PM写操作的持久性。
PMFS依赖PM写操作被持久化的顺序保证来实现consistency,之前的工作通常依靠3种方式:
- 把整个PM按write-through映射到地址空间
- 限制PM只使用non-temporal store指令,绕过CPU缓存
- 使用epoch based ordering这一新的缓存架构
以上方式分别存在以下问题:
- write-through带来overhead,同时PM写带宽较小,不适合采用write-through
- non-temporal store指令和temporal load指令不兼容,而且影响性能
- 需要大量改硬件
Q:那如果把PM按照write-back映射到地址空间,并使用CPU提供的clflush/clwb指令显式地将CPU
cache持久化到PM上,是否可行呢?
A:事实上,这样做也无法达到我们所需要的持久化保证。因为在现在的体系结构中,出于性能考虑,写入内存被当作一个posted transaction(请求被提交并接受,即被认为完成)。此时待写入的数据还在memory controller的Write Pending Queue(WPQ)里排着队,实际到PM的写入发生在之后的某个时刻。在ADR出现之前,WPQ不属于power-failure safe区域。如果在数据被写入PM之前发生了power failure,就会造成数据丢失。
如图,大小虚线红框分别代表使用ADR和不使用ADR的power-fail safe persistence domain。Asynchronous DRAM Refresh(ADR)能在断电后自动将WPQ中的数据刷写到PM上。
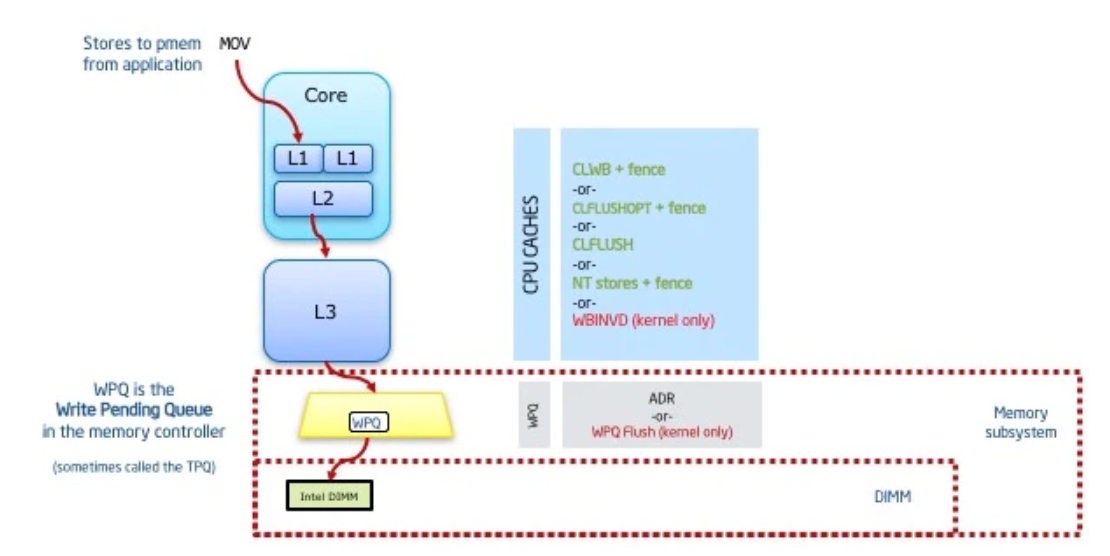
综上,本文引入了pm_wbarrier这一硬件原语(就是日后Intel的pcommit,由于ADR的普及现已废弃),用来确保写入的数据已经进入了power-fail safe persistence domain。于是,一次PM写入操作的典型流程如下:
1 | mov [X], rax ;Store |
最后需要指出,本文这一实现需要软件来追踪哪些cache line是脏的,并使用上述流程来刷写它们,这带来了额外开销。
PMFS
PMFS使用上述硬件原语和软件实现构成的workflow实现大部分功能(consistency,logging),在streaming write(连续大量写入?)等场景下少量使用了non-temporal store指令。
PMFS没有考虑磨损均衡(wear-leveling),并假设这是由硬件实现的。
PMFS Design & Implementation
PMFS的设计目标包括:
- 充分利用PM的字节粒度访问特性。比如使用更加细粒度的logging。
- 使应用程序高效访问PM。比如修改文件系统API实现,bypass page cache,使read/write只需要一次数据拷贝,mmap通过直接映射访问PM,完全避免数据拷贝。
- PM被直接映射到内核地址空间,因此需要防止来自操作系统/驱动的stray write意外写坏文件系统。
Layout
PMFS的布局如图所示。整个PM空间被分为超级块、PMFS log和数据页三个部分。包括inode在内的所有文件系统数据都被组织成B+树的形式,每个inode有一根指针指向实际存储dentry(目录文件)或文件数据(普通文件)的B+树。
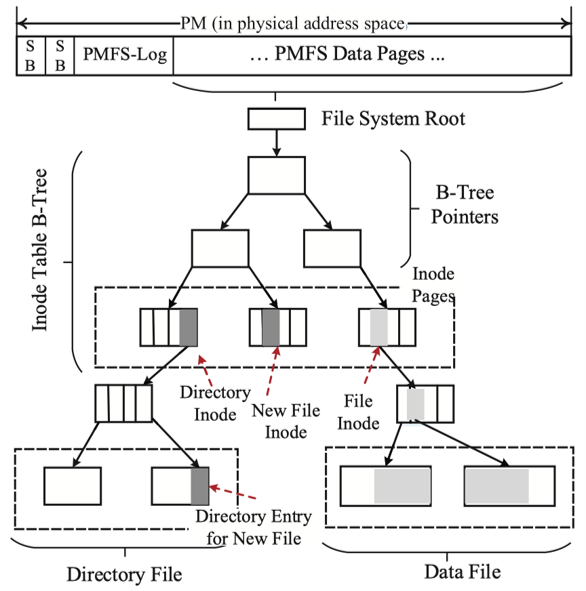
PM分配器和Virtual Memory Manager类似,以数据页为单位分配PM空间。分配器使用的数据结构维护在DRAM中,并在PMFS挂载时建立。文件系统正常umount时,这些数据结构被写回PM;当发生crash之后,需要在recovery阶段扫描文件系统重建这些结构。
在数据页大小的选择上,PMFS对元数据使用4KB页,对文件数据允许使用4KB/2MB/1GB页。使用大页无疑能降低虚拟地址翻译开销,减少页表大小,但是会带来更严重的内部碎片。因此PMFS默认使用4KB数据页,但是可以在挂载时指定页大小,也可以由应用程序通过fallocate/ftruncate显式提示PMFS使用大页。对于mmap,如果文件被只读打开/MAP_SHARED映射(不会导致copy-on-write),PMFS会使用大页进行映射,否则使用4KB页。这样做是为了导致大页被CoW带来的巨大开销。注意这里的CoW是页表机制,和下文consistency提及的CoW不是一回事。
Consistency
PMFS需要实现原子更新以保证consistency,现代FS/DB保证原子性的方式主要有:
- Copy-on-Write
- 日志(journaling)
- Log-structured File System
对于元数据的更新操作(一般写入长度较小),CoW和日志结构文件系统都会导致比较严重的写放大;但对于文件数据的更新(可能写入长度较大),journaling因为需要把数据写两次而性能不够理想。本文通过测试,选择了atomic in-place update和以cache line大小(64字节)为粒度的journaling来保证元数据更新的consistency,并使用CoW保证文件数据更新的consistency。
Undo vs. Redo
Undo日志保存的是待更新地址上的旧值,如果发生crash,恢复时将日志中的旧值还原。因为Undo日志不保存写入的新值,因此对事务中每个更新,保存旧值后就要原址写入新值并持久化。
Redo日志保存待写入的新值,crash之后可以根据日志重做更改。使用Redo日志时,对每个事务只需要做两次pm_wbarrier操作,分别持久化所有日志和所有in-place的更改,与事务中update次数无关。但Redo日志更难实现,而且事务中读取被修改位置上的数据开销会变大,因为需要到日志里去找新值。尤其对于本文的细粒度日志,这种情况会更严重。
基于以上考虑,PMFS选择了Undo日志。
Atomic in-place updates
对于元数据更新,PMFS尽可能地多使用原子更新来降低journaling的负担,只有在原子更新不能满足要求时才fall back到Undo日志。处理器原生支持不跨cache line的8字节原子更新,除此之外,本文还支持16字节和64字节的原子更新。
- 16字节:使用
LOCK-COMPXCHG16B指令支持 - 64字节:使用Restricted Transaction Memory(RTM)支持。RTM试图在一个事务中原子更新一系列dirty cache line,如果RTM失败,说明试图更新的数据大小超出了RTM支持的范围,此时需要fall back到以Undo日志的方式进行更新。
Journaling for Metadata Consistency
在实现中,PMFS log区域用作journaling,它是一个循环数组,由head和tail指针标识出起止位置。
每个元素都是64字节大小的log entry,记录了一次update:
1 | typedef struct { |
gen_id这个字段用于区分日志条目的版本,只有当某日志条目的gen_id与全局记录的gen_id一致时,才被视为有效。当循环数组绕回或者刚完成一次crash
recovery时,递增全局的gen_id,用以区分新日志和已经失效的日志。
为了保证日志条目的完整性(即不发生partial
write),可以在写入每条日志时通过两次pm_wbarrier先后持久化日志条目的内容和valid
bit,也可以通过校验和加以保证,但这样都会带来额外开销。本文利用了对同一cache
line(log entry恰好对齐到cache
line)的多次写入不会被重新排序这一硬件特性,将gen_id作为valid
bit,仅在完成一条日志条目内容写入以后,才会写入它的gen_id。这就保证了有效的gen_id不会早于日志内容被持久化:要么gen_id和整个日志条目一起被持久化,要么发生partial
write,该日志条目因为gen_id不对而被视为无效条目。为了实现这个目的,本文指示编译器不要重排对同一条日志条目的写入操作。
在一个原子操作(事务)开始时,PMFS通过原子递增PMFS
log区域的tail指针分配足够多的log
entry。对每个元数据更新操作,PMFS在日志中记录该位置上的原值,并将其持久化(clwb+fense+pm_wbarrier),然后in-place更新新值(不持久化)。完成该事务中所有元数据更新以后,PMFS刷写所有的dirty
cache
line(clwb+fense),并使用一条pm_wbarrier指令保证其持久化。最后,PMFS记录并持久化(clwb+fense+pm_wbarrier)一条特殊的COMMIT日志,标志事务已经完成。
作为优化,可以把持久化COMMIT日志的那条pm_wbarrier省掉,让后续的某个pm_wbarrier帮它保证持久化。作为代价,这样做可能导致最后一个提交成功的事务的COMMIT日志并没有成功初始化,导致其在crash recovery中被回滚。后续的某个pm_wbarrier可能来自后续某个事务,也可能来自异步的log cleaner线程。该线程的任务就是将成功提交的事务的日志标为无效:先补一个pm_wbarrier,然后原子递增PMFS log区域的head指针。
Data Consistency
文件数据的一致性是通过CoW(shadow-paging)保证的,修改文件时对被修改的页创建新副本,然后原子地将被修改的新副本关联到原文件。PMFS保证文件数据一定在相应的元数据之前被持久化,以此保证文件系统的一致性。
Write Protection
因为PMFS直接将PM整个映射到地址空间中,需要有相应的手段避免stray write破坏文件系统。
| 来自用户空间的stray write | 来自内核空间的stray write | |
|---|---|---|
| 映射到用户地址空间 | 进程隔离 | Supervisor Mode Access Prevention(SMAP) |
| 映射到内核地址空间 | 特权级 | ??? |
如表所示,只有当PM被映射到内核地址空间,且stray write也来自内核态时,没有现有的手段进行write protection。本文通过仅在将要进行写操作时打开写窗口(write window)来做到写保护。
对于写窗口的实现,最自然的想法就是通过页表中的write permission位来做,正常情况下PM被映射为只读,只在写操作时改permission位允许写入。但是对页表条目的修改会导致大量TLB失效,影响性能。
本文利用了x86处理器中的CR0.WP页表访问控制位,它能override页表权限:仅当该位为1时,处理器不能在内核态访问只读的内存页;当该位为0时,即使页表中将该页标记为只读,处理器也能在内核态下访问。
于是,通过翻转CR0.WP就可以实现写窗口。但是CR0.WP的值不会在中断或者上下文切换时被保存和恢复,因此打开/关闭写窗口时还要关闭/打开中断。因为关了中断的原因,PMFS控制每个写窗口的写入次数和写入大小,让窗口尽可能小,避免过多影响性能。
对于原生支持在不修改页表项的情况下(即不会导致TLB失效)修改页访问权限的处理器,PMFS可以利用它们的这一特性实现性能更优的写窗口。
Evaluation Setup
本文写作时,PM硬件还没有商业化使用,因此evaluation是在PM Emulator上进行的。它的原理是用DRAM模拟PM,通过在Last-Level Cache(LLC)miss后插入额外的stall来模拟PM的latency,在memory controller中限制单位时间DDR事务的数量来模拟PM的带宽。
Extra Knowledge
术语解释
NVDIMM指插在内存插槽上的,能在断电后持久化保存数据的设备。
- 最早的NVDIMM-F需要用户将一个传统DRAM和一个flash storage DIMM配对来实现持久化。
- 后来出现了NVDIMM-N,一个插在内存插槽上的设备上有flash storage和传统DIMM,断电后有备用供电将DIMM中的数据持久化到flash storage上。
- Optane属于NVDIMM-P,技术原理和DRAM不同,原生支持持久化存储数据。
三种cache line刷新指令
clflush不会与store指令或者其他的clflush发生重新排序,并且只能串行执行。clflushopt可能会与store指令(不包括对同一cache line的older store)或者clflush/clflushopt/clwb发生重新排序,并且对不同cache line的clflushopt操作可以并行执行。clwb和clflushopt类似,只是不会让被flush的cache line失效。如果后续还需要访问被flush的数据,应该使用clwb以提升性能。
clwb+fense才能保证写入次序
clwb指令可能会被与store指令被重新排序(当older
store和clwb的是同一cache
line时不会重排),也就是说以下的指令序列:
1 | write(A) |
其中只有write(A) → clwb(A)和write(B) → clwb(B)两对先后次序会得到保证,也即实际执行次序可能是:
1 | write(A) |
此时,如果上层应用要求A的写入必须在B的写入之前完成,就会发生错误。要保证这种依赖关系,要加入fense:
1 | write(A) |