The Design and Implementation of a Log-Structured File System
Intro
机械硬盘访问时延受到物理限制,和CPU时延的差距变得越来越大,这使得应用程序的性能越来越受到硬盘访问速度的制约,尤其是对于那些会产生大量随机访问的应用。不幸的是,传统文件系统(Unix FFS)就会产生这样的pattern,特别是当文件系统大量访问小文件的时候,而这正是一个很常见的workload。
作者认为,随着DRAM大小的增加,page cache可以越来越好的cover读请求,因此文件系统的bottleneck是写操作。为了最大化利用机械硬盘顺序写入性能远优于随机写入这一特性,作者提出了Log-structured File System。虽然传统文件系统中也使用日志来保证crash consistency,但日志只是临时的,文件数据和元数据还是存储在文件系统中某个固定位置上。在LFS中,文件系统的主体就是日志,包括inode、文件数据在内的所有信息都以log的形式在磁盘上append,并没有固定的存储位置。这样一来,LFS就可以把一系列写请求缓存起来,一次性(顺序)写入磁盘,省去了机械硬盘的寻道开销。
Design & Implementation
在LFS中,super block和checkpoint区域的位置是固定的,其他所有数据都在log里面。checkpoint区域保存了inode map的位置,知道了inode map在哪里,后续的文件访问流程就和传统文件系统类似。inode map由诸多块组成,可以被缓存在内存中以加速访问。
对于文件操作,LFS需要把所有新值/修改的结构追加到log中。比如创建文件时,LFS先追加新文件的inode,然后追加含有新的dentry的父目录数据块,最后追加修改后的inode map块,追踪父目录和新文件的inode。完成追加后,原来的父目录数据块和inode map块虽然还在log中,但是已经在逻辑上失效了。
在追加过程中需要考虑次序,总是保证指向某数据的指针不会在该数据之前被初始化,保证一致性。
空间管理
存储设备的空间不是无限的,随着磁盘空间被append log用尽,我们需要把分布在整个log中的空闲空间整理出来供后续使用。一种方法是把所有空闲空间串起来(threading),维护成一个链表。但显然这样做会导致越来越严重的碎片化,背离LFS原本的目的;另一种方法是空间整理(copying),将有效数据向前拷贝,把空闲空间补上。这样做的坏处是每次整理都会带来读写开销,而且一旦log前面出现空洞,后面所有数据都要往前搬,哪怕这些数据是一些几乎不怎么被修改的cold data。
Sprite LFS采用了一种混合策略,希望同时获得threading和copying的优势。它把磁盘划分为若干个固定大小的区域,称为段(segment),对每个段的写入都是从前往后顺序进行的,但是对整个log而言,用链表将所有段串联起来,这些段不需要在物理上连续。如果有一段数据是cold data,log在追加时可以把它绕过去,这样一来,它就处在log中比较靠前的位置,避免后续被频繁移动。段的大小要选择得足够大,以发挥顺序写入的优势。
段清理
本文把从a个段中copy出所有数据,识别其中的有效数据,把它们写入b个空闲段(\(b<a\))这个过程称为段清理。段清理首先面临如何识别有效数据的问题。Sprite LFS为每个段引入了段描述块(segment summary block),它记录了该段中每个块的使用情况。比如对于文件数据块,段描述块记录它属于文件的file number和在该文件中的block number。通过查看文件系统树中该文件的该块指针是否指向段描述块记录的这个块,就能判断这个文件数据块是否仍然有效。
解决了识别有效数据的问题,文章关注进行段清理的策略,并提出了该策略的四个组成因素:
- 何时执行段清理?(一直在后台运行?磁盘空间不足时运行?)
- 一次清理多少个段?(段清理提供了改变被清理的段中块的顺序的机会,清理段的数目越多,重排这些块时就有更多选择)
- 哪些段应该被清理?(直观想法:清理使用率最低(最碎片化)的那些段。这合理吗?)
- 清理时如何重排被清理的段中的有效数据块?(比如:把同一目录下的文件块放在一起;把创建/访问时间相近的块放在一起)
本文没有过多考虑前两个问题,Sprite LFS在空闲段低于某个阈值时开始段清理,每次清理数十个段,直到空闲段超过另一个阈值。作者测试发现Sprite LFS的性能对这些阈值的选择并不敏感。然而,本文认为后两个问题十分重要,它们大大影响Sprite LFS的性能。
文章提出了write cost作为评价段清理策略的指标。write cost定义为数据实际写入时间与不考虑段清理、寻道时间且跑满磁盘带宽的写入时间之商,例如write cost为1说明所有带宽都被用来写入新数据;write cost为10说明只有1份时间用来写入新数据,9份时间被“浪费”在段清理或者磁盘寻道上,即只有十分之一的带宽被用来写入新数据。
对LFS而言,只要段大小足够大,寻道时间就能忽略,因此write cost完全由段清理策略决定。于是作者将write data定义为:为了写入新数据总共需要读写的字节数,除以新数据的字节数。假设一次段清理选择了\(N\)个段,它们的使用率(有效数据所占比例)为\(\mu\),则段清理时需要读出\(N\)个段的数据,将有效数据(\(N*\mu\)个段)写回,剩下\(N*(1- \mu)\)个段可以写入新数据,故有: \[ write \ cost = \frac{N+N*\mu+N*(1-\mu)}{N*(1-\mu)}=\frac{2}{1-\mu} \ (0 < \mu < 1) \] 当\(\mu = 0\)时,不需要读出数据,只需要写入有效数据,write cost为最小值1。
根据作者的数据,Unix FFS在小文件写入场景下只能使用5%-10%的磁盘带宽(其他时间都花在寻道上面),对应的write cost是10-20;优化后的Unix FFS可以使用25%左右的磁盘带宽,对应write cost是4。
从LFS的write cost公式可以看出,被清理的段的使用率越低,write cost越小。因此对于问题3,作者自然地提出了一种贪心的段选择策略:每次清理时选择使用率最小的那些段。对于问题4,如果workload对每个文件的访问概率相同,我们没有必要也没有理由重排有效数据块;但对于hot-cold的workload(如90%的请求都在访问10%的文件),本文希望能把hot data和cold data区分出来放在不同的segment中以避免cold data被频繁拷贝,因此会按照数据块的age进行重排序(cold data的age更大)。
如下图,作者基于上述策略进行了测试。
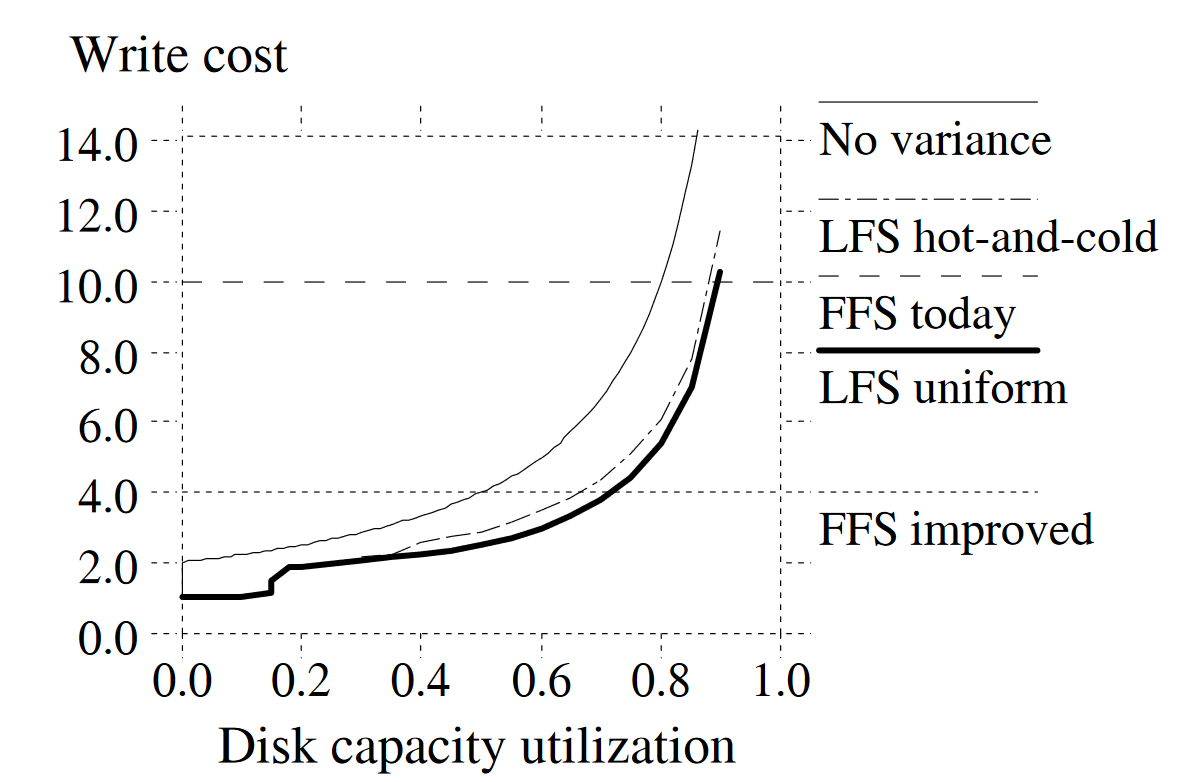
- “No variance”表示所有段的使用率完全一致时的baseline情形。
- “LFS uniform”是一个对每个文件访问概率相同的workload,使用的策略是“贪心+不重排”。因为使用了贪心的段选择策略,每次段清理选中的段的使用率一定是小于磁盘整体使用率的,于是该workload的write cost是小于baseline的。
- “LFS hot-and-cold”是一个90:10的hot-cold workload,使用的策略是“贪心+按age重排”。出乎意料的是,局部性更强的workload和策略却导致了比“LFS uniform”这一没有局部性的workload更差的结果。
作者这么解释“LFS hot-and-cold”的结果:随着时间推移(即随着文件的增删改),90%的cold data因为只占了10%访问,其使用率的下降速度是远小于10%的hot data的,这就导致贪心策略大部分时候都选中了包含hot data的段。直观来看,hot data在被清理之后很快又需要再次被clean,而cold data在被清理之后,很长一段时间都不需要再次清理。换句话说,cold data所在段中的free space要比hot data段中的“更有价值”,更值得被清理器选中。
于是,对于问题3,作者提出了一种新的选择策略,将段的价值也考虑其中。本文认为,段的age(用段中最年轻的数据块的age代表)越大,它就越稳定(cold data),因此清理该段获得的空闲空间也更有价值,如下式: \[ 性价比=\frac{benefit}{cost}= \frac{free \ space \ generated \ * age \ of \ data}{cost} =\frac{(1-\mu) * age}{1+\mu} \] 其中cost来自读取整个段(1)并写入有效数据部分(\(\mu\))。该cost-benefit策略取得了优于greedy策略的write cost。为了实现该策略,Sprite LFS额外维护了segment usage table这一结构,用于追踪每个段的使用率和年龄(age)。
Crash recovery
LFS使用checkpoint保存一个一致的文件系统状态,避免crash recovery时需要从头扫描整个log。Checkpoint保存在一个固定区域中,它还保存了inode map,segment usage table等位置不定的数据结构的位置。保存checkpoint之前,需要保证把内存中的结构刷写到磁盘上。为了避免保存检查点出现crash,LFS能同时存储两个检查点,恢复时使用修改时间最近的那个;并且写入时最后写入检查点修改时间,以避免partial write。
恢复到最后一个检查点的状态后,可以通过前滚(roll-forward)该检查点之后写入的日志,尽可能恢复到最新的状态。前滚利用了segmeng summary block做恢复,比如该结构记录了一个不在inode map中的inode结构,前滚时就需要update inode map将该结构包括进去。