Efficient Persistent Memory File Systems using Virtual Superpages with Multi-Level Allocator
Intro & Motivation
PM文件系统如果使用大页存储文件数据,可以使文件索引更短且占用的空间更小,同时提高了TLB命中率。然而这样做的问题也很明显:大页分配给文件后产生了更大的内部碎片,并且对于基于CoW的一致性保证机制而言,使用大页会带来严重的写放大。
此外,本文认为现有PM文件系统长期使用后性能下降(aging)的问题是分配器导致的。分配器往往需要支持多种不同的分配大小(称为multi-grained allocator),而传统PM文件系统往往使用单一链表组织空闲/使用中的数据页,每个链表节点是一系列连续页,混合分配大页和普通页时就会产生外部碎片,影响大页的分配速度。
本文提出了一种Virtual Superpage Mechanism(VSM),使用虚拟的大页支持多粒度的CoW以处理写放大的问题;此外,本文提出了VSM Allocator(VSMA)以支持大页/普通页两个粒度的空间分配,提升分配效率的同时缓解单一链表分配器造成的aging问题。
Virtual Superpage Mechanism
本工作采用虚拟大页存储文件数据。所谓虚拟大页是虚拟地址空间中一段连续区域(典型值2MB/1GB),但是对应的物理页(4KB)不要求是连续的。分配给文件的是虚拟大页。记录PM中虚拟页-物理页映射关系的页表也被保存在PM上。
Multi-grained Copy-on-write
基于虚拟大页,本工作提出了MCoW保证文件系统一致性。简单来说,对于涉及整个大页的文件数据in-place update操作,MCoW创建新的大页,写入新数据,原子更新文件索引(即通常的CoW流程);但对于只涉及大页一部分的in-place update操作,MCoW只创建新的普通页,写入新数据,然后通过修改页表的方式,让新的普通页取代相应虚拟地址下旧的物理页。
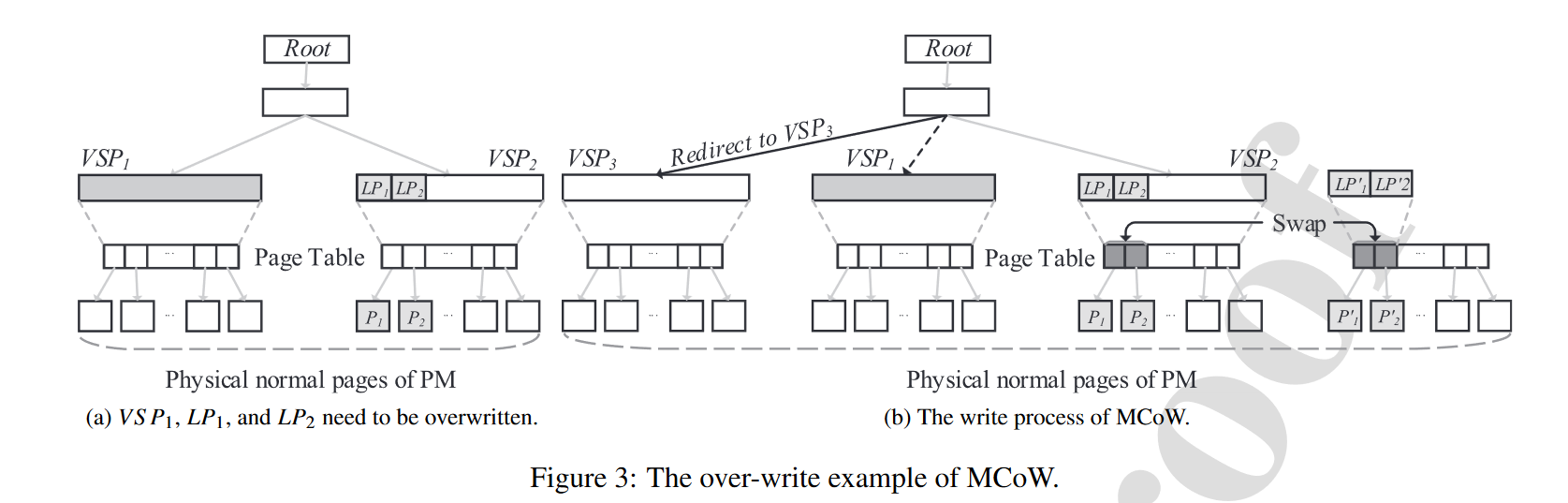 如图所示,某文件包含\(VSP_1\)和\(VSP_2\)两个2MB虚拟大页,一次写入操作覆盖了整个\(VSP_1\),以及\(VSP_2\)中的虚拟普通页\(LP_1\),\(LP_2\),它们分别对应物理普通页\(P_1\),\(P_2\)。这次写入操作的流程包括:
如图所示,某文件包含\(VSP_1\)和\(VSP_2\)两个2MB虚拟大页,一次写入操作覆盖了整个\(VSP_1\),以及\(VSP_2\)中的虚拟普通页\(LP_1\),\(LP_2\),它们分别对应物理普通页\(P_1\),\(P_2\)。这次写入操作的流程包括:
- 针对整个\(VSP_1\)的覆盖写入,分配虚拟大页\(VSP_3\)(及其对应的物理页,此时是连续的512个4KB页);针对两个虚拟普通页的覆盖写入,分配虚拟普通页\(LP_1'\),\(LP_2'\)和对应的物理普通页\(P_1'\),\(P_2'\)。
- 在transaction log中记录每一组虚拟大页/普通页的替代操作,如\((VSP_3, VSP_1)\),\((LP_1', VSP_2)\),\((P_1',P_1)\),\((P_2',P_2)\)。这里第2条记录是因为\(LP_1'\)和\(LP_2'\)连续,可以视作一个“虚拟大页”的头部。
- 将新的文件数据写入新分配的\(VSP_3\),\(LP_1'\),\(LP_2'\)对应的物理页。
- 更新文件索引,让\(VSP_3\)取代\(VSP_1\);更新页表,交换\(LP_1\)和\(LP_1'\),\(LP_2\)和\(LP_2'\)对应的物理页。
- 回收虚拟页\(VSP_1\),\(LP_1'\),\(LP_2'\)。
完成上述流程后,虚拟页\(LP_1\),\(LP_2\)仍然是文件的一部分,但底下的物理页已经被更换了。虚拟大页\(VSP_3\)取代了\(VSP_1\)成为了文件的一部分。
Crash Recovery
如果需要进行crash recovery,文件系统根据写操作的offset和size判断出文件中哪些虚拟大页被整体替换,哪些虚拟大页只需要替换一部分物理页,然后根据transaction log将文件系统恢复到一致状态。在上例中,transaction log中的信息指出\(VSP_2(P_1)\)和\(LP_1'(P_1')\),\(VSP_2+4KB(P_2)\)和\(LP_1'+4KB(P_2')\)这两组4KB虚拟页之下的物理页需要交换(括号中为虚拟页对应的物理页)。
Zero-copy File Data Migration
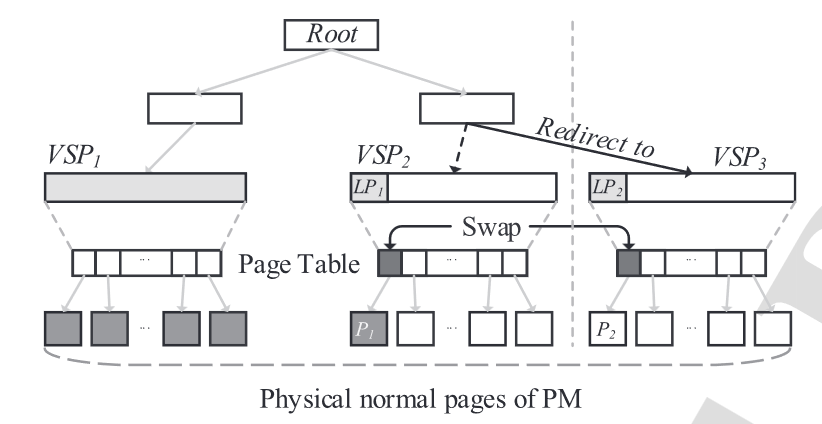
如图所示,ZFDM是本文提出的,减少虚拟大页被分配给文件后内部碎片的机制。
- 当包含了虚拟大页\(VSP_1\),\(VSP_2\)的文件被关闭时,最后一个虚拟大页(\(VSP_2\))中未被使用的空间便被释放(即除\(LP_1\)以外的其他普通页),并标记该文件没有空间可供写入。
- 当重新打开该文件并写入时,文件系统分配新的虚拟大页\(VSP_3\),并交换\(LP_1\)和\(LP_2\)(\(VSP_3\)中第一个虚拟普通页)之下的物理普通页,以将原先\(VSP_2\)中的文件数据zero-copy到\(VSP_3\)中。
- 修改文件索引,让\(VSP_3\)取代\(VSP_2\),之后的追加写入便落在\(VSP_3\)中。
一个优化点:交换物理普通页可以批量进行,即如果虚拟大页是1GB,而需要交换的物理普通页超过512个,可以直接通过交换3级页目录项来实现。
Mult-level Allocator
本文认为,现有工作的allocator分为fixed-size和multi-grained两种。两者都使用(逻辑上的)单一链表将空闲页串联起来,前者每个链表节点是一个空闲页,这样做在分配多个页时效率很低;后者每个链表节点是一系列连续空闲页,可以减少分配多个页时的链表操作次数,但是会带来外部碎片问题,并且需要遍历链表找到一个足够大的节点以满足分配请求。
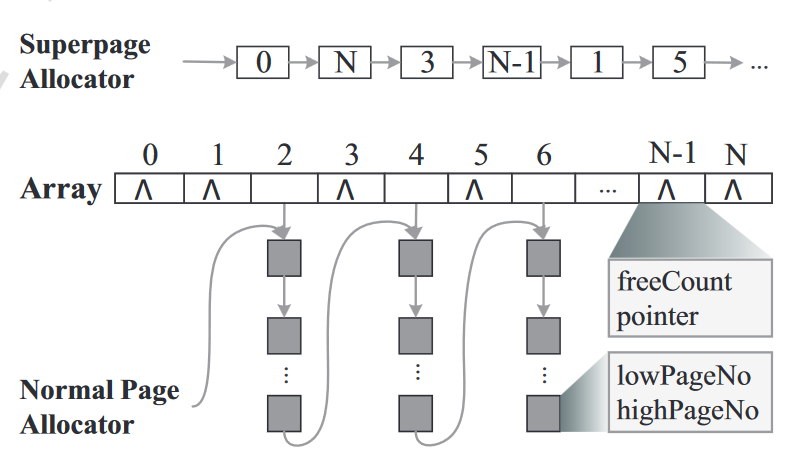
基于上述原因,本文提出了如图所示的multi-level allocator(VSMA)。PM被映射到等大小的虚拟地址空间,虚拟地址空间被分为若干个group,每个group的大小等于虚拟大页的大小。这些group中一部分被用于虚拟大页分配,一部分被用于普通页分配。
对于虚拟大页分配,VSMA使用单一链表串联用于虚拟大页分配的空闲group。
对于普通页分配,VSMA使用链表串联每个用于普通页分配的group中的空闲segment(segment是一系列连续的内存页)。在此之外,VSMA还维护了一个数组,该数组元素数目等于group总数,且对每个用于普通页分配的group,该数组存储group中空闲普通页数目(freeCount),和指向该group中首个segment的指针(pointer)。这样一来,分配普通页时可以从链表中途开始搜索,分配流程如下:
- 先遍历数组,根据freeCount找到一个空闲普通页足够多的group。
- 使用pointer遍历该group中每个segment,如果有足够大的segment则进行分配。
- 否则继续遍历数组寻找下一个freeCount足够多的group。
释放空间时需要将segment释放到其从属的group中,并利用freeCount将相邻的空闲segment合并。
其他优化
- 用于虚拟大页/普通页的group比例动态变化:预先指定好比例上下限,超出范围时互相转化。
- VSMA在上述实现的基础上还进行了per cpu化,以增加并发度。
疑问
- 本文通过修改页表进行细粒度CoW的实现方法可能会导致很严重的(data) TLB Miss,但是Evaluation没有体现这一点,而是测试了看似无关紧要的instruction TLB Miss。