Strata: A Cross Media File System
Intro
本文的key idea是提出了一种跨介质的文件系统,在Strata的实现中,它由NVM,SSD和HDD三个层级组成。作者认为,这样做的优势有:
- SSD有erasure block的概念,现代HDD有shingled magnetic recording的概念,它们的共性是让对SSD/HDD的in-place update必须先擦除掉大块区域(erasure/shingled block,一般为多个块大小)才能写入,导致严重的写放大。跨介质的文件系统可以在最上面的NVM层handle大部分文件请求,对于需要写入磁盘的数据,可以按照erasure/shingled block的大小批量写入以减少写放大。
- 利用NVM,实现了synchronous & in-order update的文件系统语义,降低了维持文件系统一致性的难度和crash recovery的开销。
作者认为,现有文件系统的问题包括:
- 绝大部分workload由1KB左右的small update组成,NVM的速度可以handle这些请求,但是使用NVM会导致内核态开销占比很大,即内核成为瓶颈。
- Workload的大小越来越大。虽然NVM很快,但是成本很高,因此需要采用混合文件系统,同时发挥NVM和SSD/HDD的优势。
- 现有文件系统提供的异步接口让维持crash consistency更困难,开销更大。
Design
Overview
Strata的设计目标包括:
- Fast write,现有web服务的特点是先持久化数据再发送回复,即大量较小的随机写入操作,Strata应善于处理这一情形。
- Efficient synchronous
behavior,现有文件系统需要显式的用户请求来保证持久性(如
fsync),Strata支持按序、同步的写入持久化。 - Manage Write Amplification,将对SSD/HDD的写入从关键路径上分离出去(异步),并且对齐到erasure/shingled block的大小批量写入以减少写放大。
- High Concurrency,每个文件拥有独立的log,因此便于实现高并发。
- Unified Interface,为Strata所跨所有层级的设备提供统一的接口。
Strata在NVM中同步记录每个inode的write log,称为update log。这样做的好处是写入时延较小且确定,并且很适合大量较小的随机写入,同时也便于保持一致性和crash recovery。为了最大化性能,记录log是在用户态完成的,Strata的用户态部分称为LibFS。
Log这一形式不适合搜索和读取操作。Strata会周期性异步地把log转写到shared area上,并转为便于读写的树状结构,这一过程称为digest。Digest可以多线程并发进行,还可以将update log批量写入以减少写放大。在digest过程中,可以合并log中的操作以减少写入次数(如log中创建、写入、删除了同一个文件,digest时什么事都不用做)。
Digest完成后,NVM上对应的log可以被回收;如果digest时发生crash,恢复时只要重做digest,并覆写shared area中被部分写入的数据即可。Digest是在内核态完成的,Strata的内核态部分称为KernelFS。
KernelFS可能会将文件数据块在不同层级的shared area中迁移。
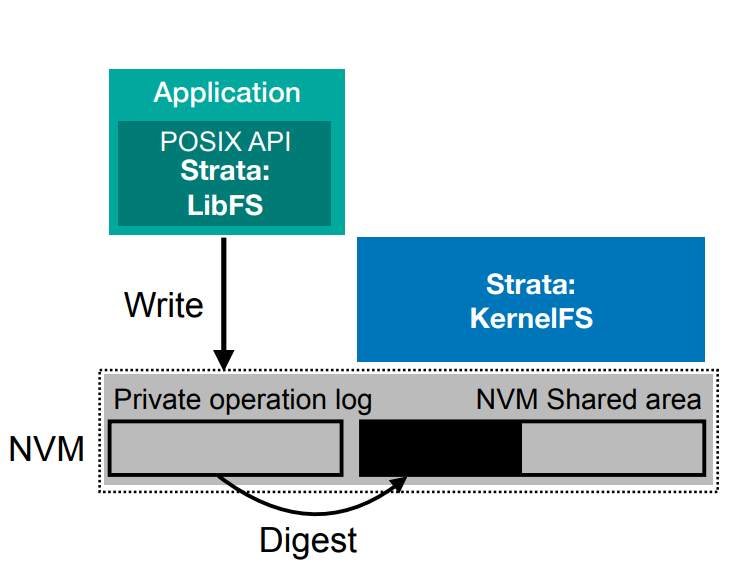
为了保证kernel bypass中的安全性,Strata把存储设备上的连续空间分配给应用,并指定仅该应用可访问。对于NVM通过页表和MMU来实现保护,对于SSD通过NVMe中的namespace实现保护。
Metadata Structure
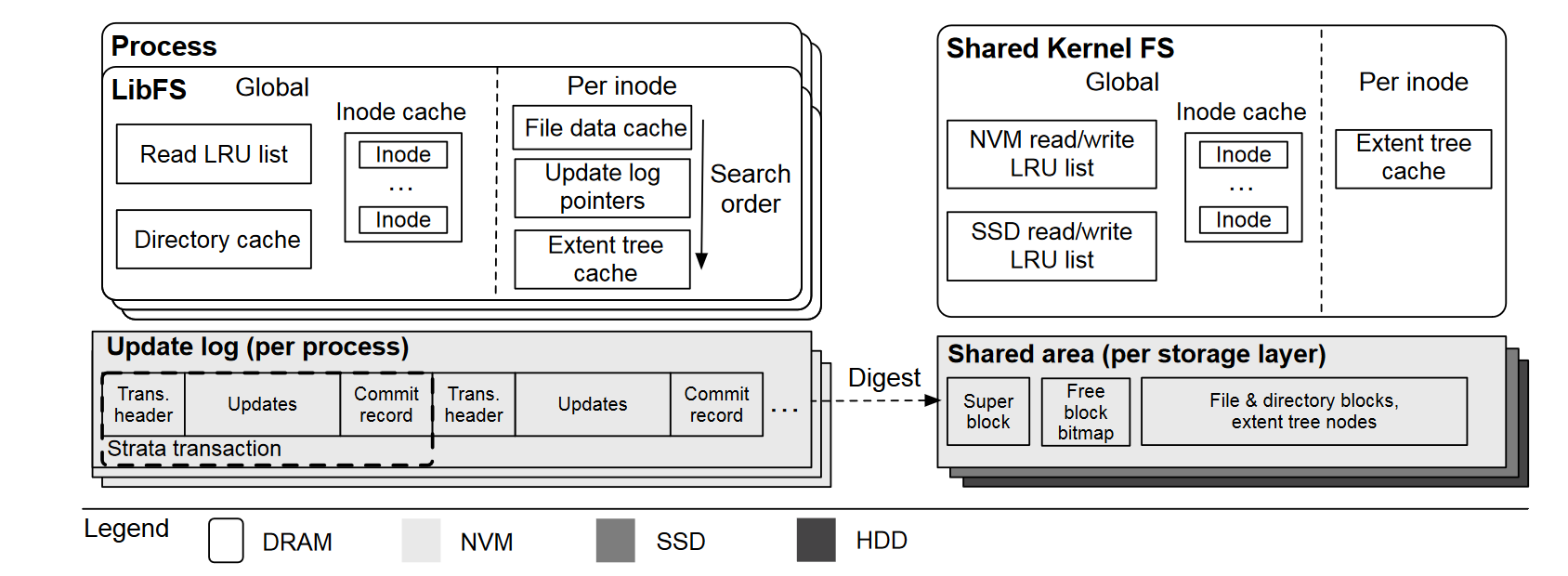
Strata将super block保存在NVM上。
Inode没有固定的存储区域,它们存储在一个特殊的,extent tree结构的inode file中,组成inode file的块可能被迁移到其他介质。
文件inode包括update log指针和多个extent tree root,每个文件对每种介质都有一棵extent tree。
Directory cache将目录名映射到目录inode以加速查找。
Inode cache缓存该文件修改时间,位置(log?shared area?)等元数据。
LibFS
Sync Write
传统存储设备的读写速度很慢,因此文件系统往往采用异步的IO语义。Strata的写入通过在NVM上记录update log实现,因此可以同步完成,便于保持写入操作的顺序和crash recovery。对NVM的写入操作可以bypass kernel,同时也不需要经过page cache。
Strata写入的时operation log,即只记录操作(如:Add filename, dir inode number`)而不包含文件数据。
Strata的update log被设计成幂等的,可以多次apply而不改变结果。比如使用inode号和偏移量记录对某文件某位置的写入。
Digest and GC
- 使用的Log达到某一阈值时,LibFS请求KernelFS开始digest。Digest在后台异步进行,完成时KernelFS通知LibFS,对应的log可以被回收。
- KernelFS进行digest时或者LibFS进行GC时,应用仍然可以追加写入正在被操作的log。
- 如果digest log时发生crash,恢复时重新digest即可,log的幂等性保证文件系统能恢复到一致状态。
Fast Read
- 对SSD/HDD的读操作(不包括NVM)会在DRAM中维护读缓存(Read LRU List),如果后续被修改,被修改的部分按LRU方式换出cache,并被写入update log。
- 每个inode还在DRAM中维护了extent tree cache,缓存对extent tree的访问。
- 一个文件的不同块可能位于不同层级的extent tree中(迁移操作导致),某些块甚至可能同时存在于多个层级中。Strata保证上层的数据块一定比它在下层中的副本更新。
- 综上,对文件的读操作会先检查Read LRU List,然后是update log,再从上到下依次检查各个介质的extent tree(包括其cache)。
KernelFS
Digest
- Digest将update log转变为shared area上易于查找和读取的extent tree形式。
- Digest前先扫描log,以合并log(减少写放大)和消除不需要的log(如创建和删除文件抵消)。
- 先扫描再digest也让KernelFS:
- 能够估计需要的(meta-)data block数目,并请求allocator批量分配。
- 判断对两个不同log的digest是否会冲突,从而可以并行进行。
Data Migration
- KernelFS会将cold data移动到更底层的存储设备,以最大化利用存储空间。
- KernelFS为每种介质(除最低层次外)在DRAM中维护一个LRU list,被换出的块会被迁移到更低层次的设备上去。LibFS会记录对每个数据页的访问情况,并传递给KernelFS。
- 对不同存储设备,根据其块大小不同,KernelFS维护的LRU list粒度也不同(如对NVM,LRU中每个块是1MB;对SSD则是4MB)。
- 数据迁移会对齐到SSD/HDD的erasure/shingle blk大小。
Lease
- Lease是一种类似读写锁的文件共享机制,能将对同一文件/目录的并发访问序列化。
- Lease分为write lease(exclusive)和read lease(shared)。
- 在释放写lease时,进程会等到写入的数据被完全digest之后才放锁。这就保证放锁之后写入的数据对其他进程可见。
Limitation
- Strata不支持Memory-mapped file。
- 一方面,memory-mapped file的最小写回粒度是页大小,不利于Strata大量较小随机写入的优势场景。
- 另一方面,如果两个进程共享映射了同一个文件,Strata的设计使一个进程的写入没有办法立刻对另一个进程可见。因为只有当
msync()等同步机制被显式调用后,文件系统才会将脏页写回(在Strata中,即为写update log)。
- Fault Tolerance。Strata暂时没有应对存储设备故障的手段,因此整个文件系统的寿命取决于整个系统中寿命最短的介质。
Evaluation
本文evaluation部分主要测试了:
常见应用在Strata上的性能。
高并发度场景下Strata的性能。
跨介质的混合文件系统(log + digest)的性能,并和为单层存储设计的文件系统比较。
在不同层级间移动数据的开销,并和更上层(user-level)和更下层(block layer)的解决方案进行比较。
多个用户共享使用Strata时的隔离性。
Strata和PMFS、NOVA、EXT4-DAX(NVM),F2FS(SSD),EXT4(HDD)进行了比较。