ctFS: Replacing File Indexing with Hardware Memory Translation through Contiguous File Allocation for Persistent Memory
Intro
本文认为,由于PM的访问速度已经和DRAM所差无几,因此在为PM设计的文件系统中,读写性能瓶颈不再是I/O,而是解析文件索引(文件索引:从文件偏移量到存储设备上具体位置的映射)。即便通过mmap()直接访问文件,也不过是将文件索引的开销转移到了page
fault处理流程中。
传统文件系统大多采用树状索引结构,而如果能为每个文件连续分配存储空间,文件索引的负担就能大大减轻。然而,连续分配的空间如果是定长的,会导致内部碎片问题;如果是变长的则会带来外部碎片。此外,如果文件大小增长以至于超出了分配的存储空间,文件系统不得不分配一块更大的空间给它,这又导致了数据拷贝的负担。因此,只有一些为CD-ROM等介质设计的只读文件系统采用了连续分配存储空间的策略。
本文提出了ctFS(contiguous FS),一种为PM设计的,旨在为每个文件连续分配存储空间的文件系统。它的主要设计有:
- 每个文件(目录)都被连续分配一段虚拟地址空间。
- 在PM上维护PPT(persistent page table),记录文件的虚拟-物理地址映射。
- 新的系统调用
pswap(),用于交换两段虚拟-物理地址映射关系,以实现文件的resizing和原子写入。
于是,在ctFS中,文件索引仍然是树状结构,只不过是以页表的形式体现的。解析文件索引通过硬件(MMU&TLB)完成,因此效率大大提升。作者认为这样的设计并不会导致ctFS需要使用更多的TLB entry,因为:
- 对于non-DAX的传统文件系统,page cache这一内存缓冲的存在需要占用TLB entry。
- 对于EXT4-DAX,虽然没有page cache,但需要通过虚拟地址直接访问设备,这需要占用TLB entry。
Design
Overview
ctFS实现同步写操作,即写操作完成时,写入的数据已经被持久化到PM上。fsync()等同步API没有效果。
ctFS有sync和strict两个工作模式。元数据的更新总是原子的,文件数据的更新只在strict模式下是原子的。
ctFS分为内核态的ctK和用户态的ctU两个部分,ctU负责分配虚拟地址空间,通过内存操作实现文件系统语义;ctK负责维护PPT、内存页表,和分配物理页。
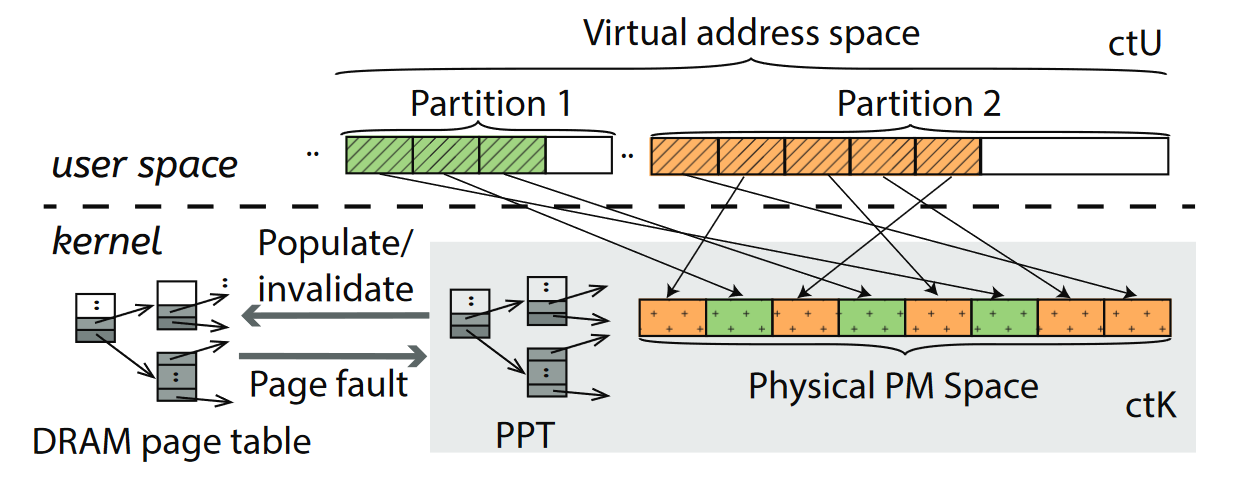
ctU

ctU将文件系统的虚拟地址空间分成若干个partition,partition形成一个层次结构,最低的L0大小为4KB,相邻两个层级的大小相差8倍。于是,L9 partition的大小为512GB。之所以相邻层级相差8倍,是为了能够让每3个层级对齐到一级页表的大小(512字节)。每个文件/目录被分配到一个刚好能容纳它的partition中,因此其虚拟地址空间是连续的。
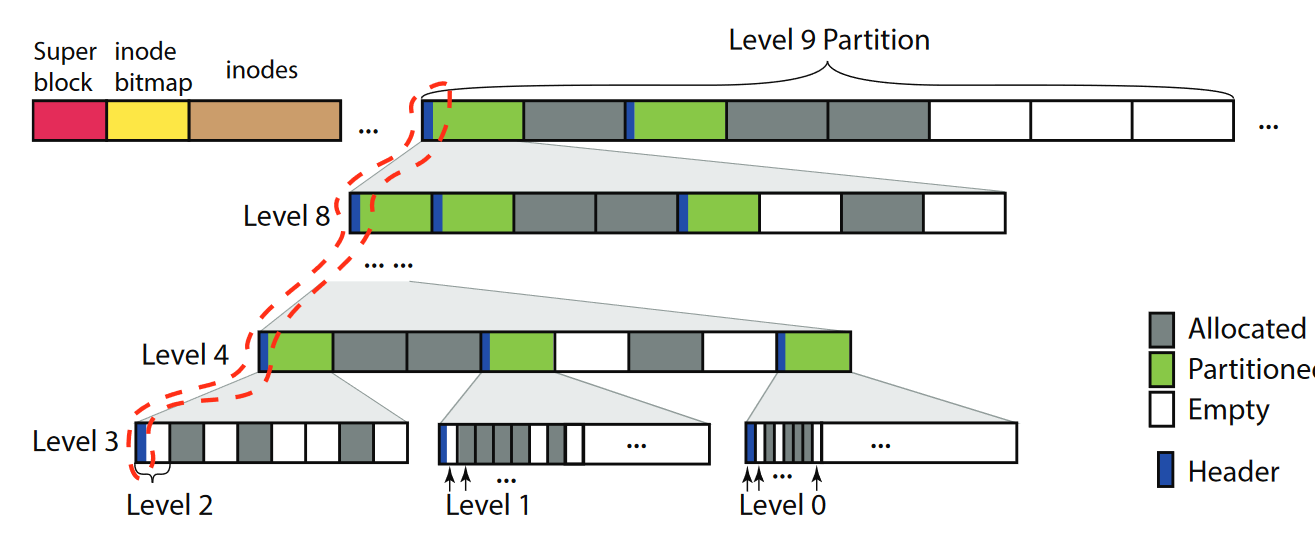
每个partition有Allocated,Partitioning,Empty三种状态。A状态指该partition已经被分配给了一个文件/目录;P状态指该partition被分割为8个子partition加以使用;E状态指该partition未分配,因此其下没有对应的物理地址。
每个处于P状态的partition都有一个header,记载其子partition的状态。这个header被存储在partition的第一个页中,因此它的第一个子partition必须也处于P状态(如果处于A状态,存这个header的空间就要给文件用了)。
header页可能并排存储着多个层级partition的header,如图中红色虚线所示。每个header都比较小,因此多个层级的header足以塞进一个4KB的head页中。
对于较低层级的partition,一个4KB页会占据大部分空间。因此L2-L0的partition不再可分,不具有P状态,而是直接由L3 partition分割得到。每个L3 partition只有一个header,还有一个bitmap记载其8/64/512个L2/L1/L0的状态(A或E)。
每个partition都对齐到其大小(如L9 partition对齐到512GB,首地址的低39位为0)。这一设计使得可以通过修改高级页表中的项来批量修改其所有子partition的映射情况(修改1条三级页表项 == 修改512条四级页表项)。
ctFS初始化时会创建两个L9 partition,一个用于存储元数据(超级块,inode map,inode),另一个存储文件数据。每个inode都有一个指向该文件所拥有partition的指针。
ctK
ctK负责维护PPT。PPT的形式和内存页表相同,唯二的不同是持久化存储在PM上,以及使用相对地址而非绝对地址(因为不同进程中,PM可能被映射到不同的虚拟地址起始位置)。在page fault handler中,ctK需要把PPT内容推送到内存页表中供MMU使用。
ctK提供一种新的系统调用pswap(),用于交换两个大小相等的连续虚拟地址空间到其物理地址的映射关系,签名是:
1 | int pswap(void* A, void* B, unsigned int N, int* flag); |
A和B是两个虚拟地址空间的起始地址,N为长度。flag是一个返回值,pswap()会在交换成功时将其赋值为1。ctU使用pswap()时会将redo
log中一个位于PM上的变量的地址传给它,用于在crash
recovery时判断pswap()是否成功完成。
pswap()操作本身是原子的,且其结果是durable的(直接操作PPT)。多个并行的pswap()会被序列化执行。因此pswap()和redo
log结合即可保证crash consistency。
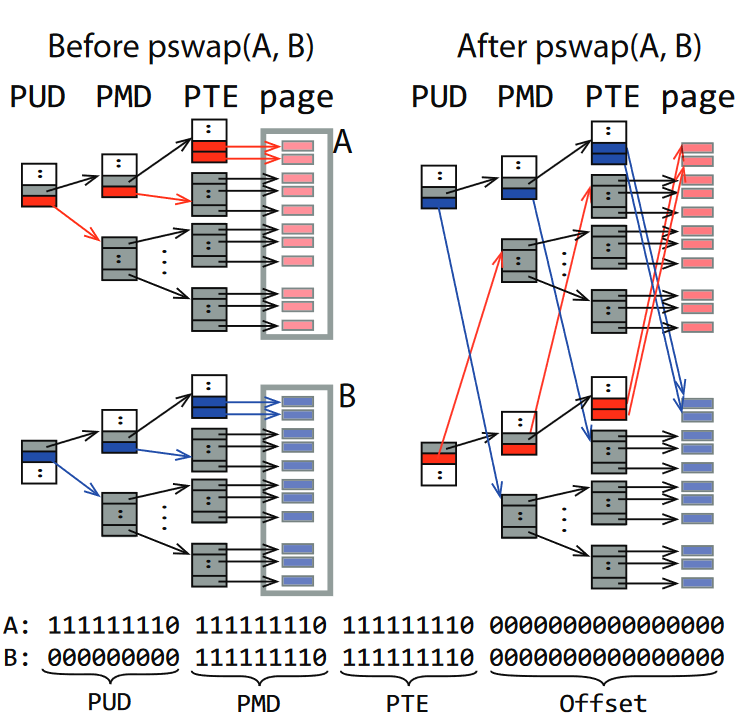
如上图所示,作为优化,pswap()可以通过直接交换高级页表项来实现批量交换。显然,这么做的前提条件是A和B两个虚拟地址空间在该级页表项中的偏移量相同。
文件操作
对于普通读写操作,ctFS根据文件描述符找到inode,进而找到文件partition首地址,然后加上偏移量获得虚拟地址,通过MMU转换得到PM物理地址并用于访问。
两类特殊的写操作需要用到pswap():
- ctFS在一个文件第一次被写入时为其分配partition,其大小刚好能容纳该文件。如果文件大小增长以致于超出此大小,就需要进行upgrade,分配一个更大的partition给它,然后通过一次
pswap()操作交换两个partition,再更新inode中的指针指向新partition。交换后,旧partition现在没有被映射,新partition映射到原先文件的物理页,没有发生data copy。 - 在strict
mode下,ctFS要原子完成写入。如下图所示,假设写入的文件偏移量为O,长度为N。ctFS首先创建一个等大的partition,将待写入的数据写入新partition。如果O没有对齐到页边界,还要将O所属的页中其他数据拷贝过来。随后,ctFS通过
pswap()把新partition中被更改的部分交换到原文件中。(图例中为p1-p3,不包括p0)
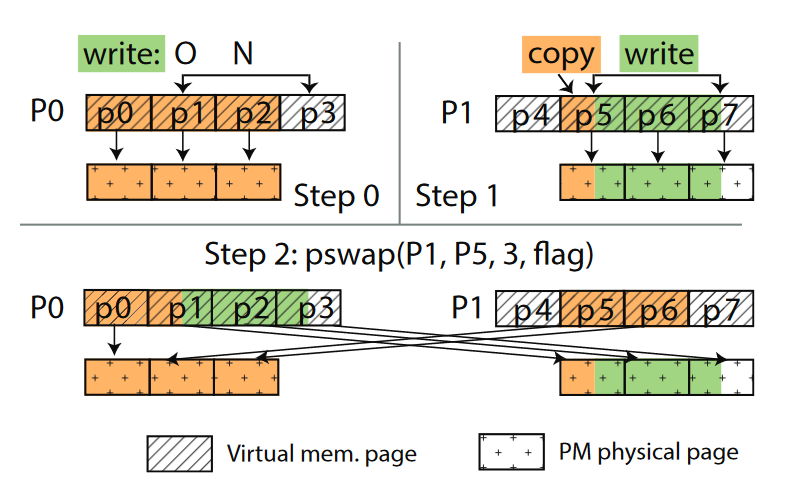
两类特殊写操作的崩溃一致性通过redo log保证。
其他优化
- 大页。使用2MB大页可以让L3及以上的partition获益(减少页表层级和TLB项)。当
pswap()交换的区间大小小于2MB,且使用了大页时,必须将大页拆散成4KB页以完成交换。 - strict mode下的写入操作要通过write+pswap完成,但如果是追加写入(没有覆盖),可以直接追加在原文件数据页后面,再更新文件大小。只有在更新文件大小时,追加才被视为生效,因此不会造成不一致。
Protection
ctFS使用memory protection key保护文件系统免受来自意外的stray write的破坏,但是不能防止恶意攻击。
ctFS将PM所有内存区域绑定到一个MPK key,且不可读也不可写;只在文件操作时修改MPK key的访问权限为读/写(即访问窗口),操作完成后再改回去。
修改MPK
key访问权限可以在用户态进行,因此代价比mprotect()这种系统调用(修改页表项中的权限)要低。
Evaluation
本文将ctFS和SplitFS,Ext4-DAX,PMFS和NOVA进行了比较。ctFS在Append(4KB追加写入)这一workload下的提升最大。
本文还确认了使用大页带来的性能提升。
Limit
- ctFS将部分功能实现在用户态,这牺牲了部分安全性以换来性能。因此作者认为ctFS适合部署在数据中心中:由数据中心负责恶意应用的防护,因此运行的都是可靠应用。
- ctFS会有一些内部碎片的问题。但作者认为这是可接受的,因为内部碎片只会造成虚拟地址空间的浪费,它们没有映射到物理页,因此不会浪费物理存储空间。此外,ctFS的分配算法与buddy allocator类似,因此它带来的内部碎片与传统内存分配算法是差不多的。