SplitFS: reducing software overhead in file systems for persistent memory
Intro
作者认为,现有文件系统操作在PM上会带来严重的software
overhead,尤其是对于写操作而言。如图所示,对PM的4KB写入操作在硬件部分的延迟是671ns,则append操作延迟的其他部分就被认为是software
overhead。 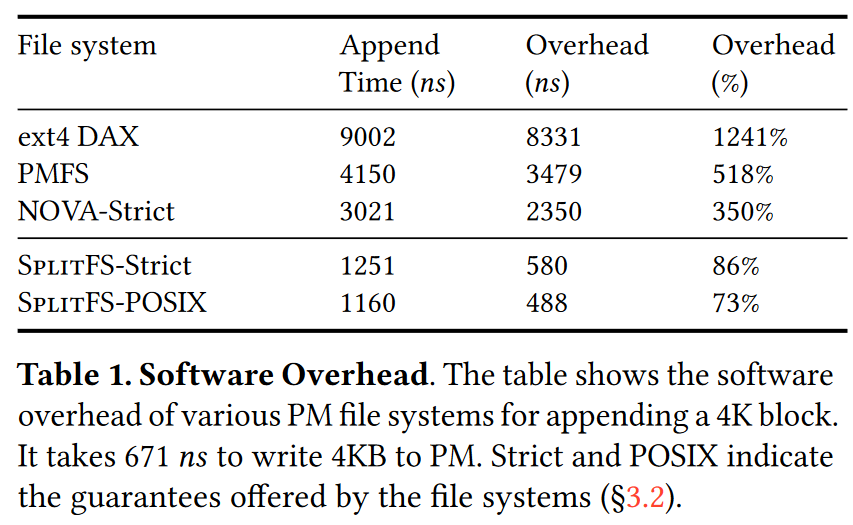
SplitFS对这个问题的处理思路是提出一种新架构:让用户态的libFS处理文件数据操作(如read,write),内核态(即ext4-dax)文件系统处理元数据操作(如open,close)。这一设计是基于绝大部分文件操作是数据操作这一假设,因此可以牺牲元数据操作的性能来加速文件操作。
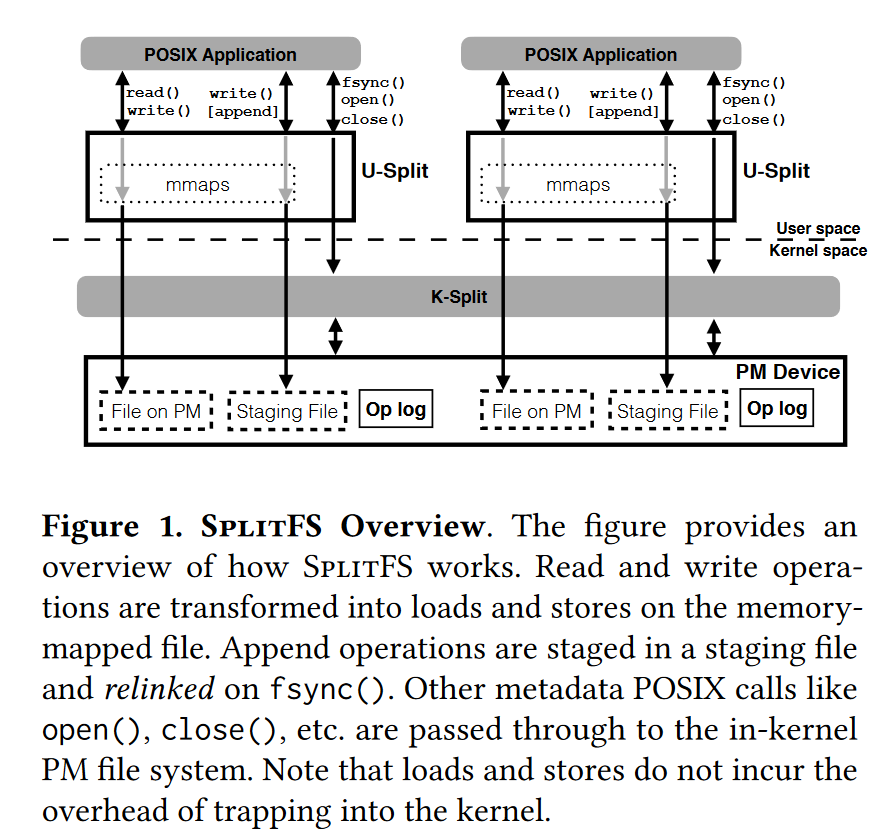
Design
Goals
- Low software overhead,为数据操作,尤其是写入操作做优化。
- Transparency,不需要改应用。
- Minimal data copying and write IO,减少写PM的次数,避免文件系统内的数据拷贝,以此减少PM的wear out,同时也有助于实现原子操作。
- Low implementation complexity,使用ext4-dax作为内核态文件系统,减少代码量的同时得到了充分测试和持久维护。
- Flexible guarantees,为应用提供了3种可选的一致性保证。
Modes and Guarantees
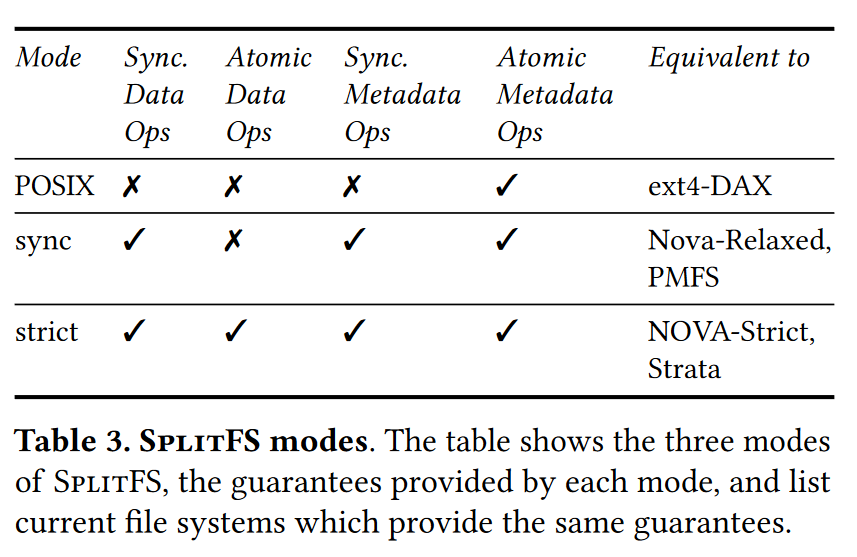
SplitFS提供了如下所示的三种一致性保证:
- POSIX
mode只保证元数据操作的原子性,这也是底层ext4-dax的保证。此模式下overwrite是in-place同步进行的,append是异步的,只在
fsync()时被持久化。 - Sync mode在POSIX
mode的基础上保证同步性,写操作不需要
fsync(),在调用返回时就已经被持久化。该模式下不保证数据写入的原子性。 - Strict mode在Sync mode的基础上保证数据操作的原子性。
此外,SplitFS保证append操作的结果在fsync()时对其他进程可见,其他进程的结果在完成时立刻对其他进程可见。这一可见性保证和原子性、同步性的保证使得SplitFS不需要类似Strata种lease的机制来实现文件共享。
Overview
Staging & Relink
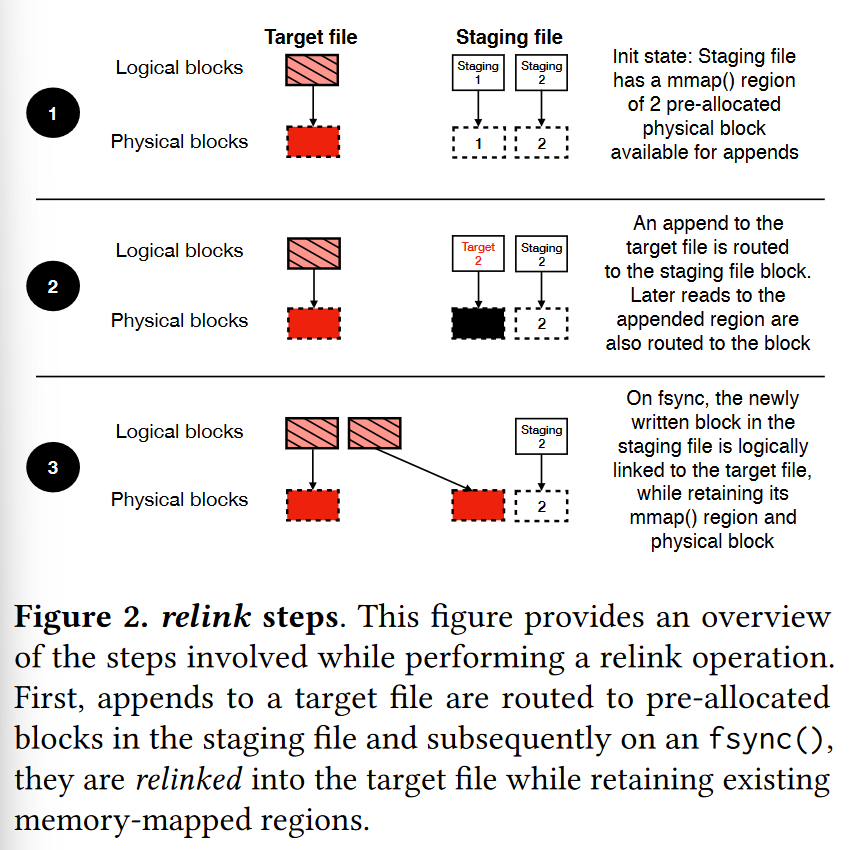
对于append或者strict
mode下的原子overwrite操作,SplitFS使用临时的staging
file存储写入的内容,并在fsync/close时使用relink()原语将数据关联到原文件。Staing
file位于PM中,作者考虑过把它们放到DRAM中,但是这样会带来一次额外数据拷贝,因此作罢。
relink()是本文提出的新原语,其目的是消除从staging
file到原文件的数据拷贝,它的签名是relink(file1, offset1, file2, offset2, size),将指定的数据从file1移动到file2。
relink是元数据操作,因此原子性是ext4 journal transaction保证的。如下图,只要offset和size对齐到block边界,relink就能完全避免数据拷贝。
mmap
对于read或者非strict mode下的overwrite操作,SplitFS是通过建立mmap+内存操作(memcpy/non-temporal store)完成的。对文件某偏移量的首次访问请求会引发对该偏移量附近区域的mmap映射,后续的访问不需要重新映射,只进行内存操作即可。
由于staging file的存在,一个文件的有效内容可能分布于原文件和staging file中,SplitFS需要为每个文件维护所有已建立的mmap映射集合,将文件操作路由到正确的文件中去。
Optimized Logging
对于需要保证原子性的操作,SplitFS需要记录redo log,每个用户态SplitFS(U-SplitFS)实例都拥有自己的日志,记录的日志是operation log,不包括data。
日志区域是在文件系统挂载时预先分配好的一部分空间,如果用完了,需要对当前用户态实例打开的所有脏文件(即拥有staging
file的文件)调用relink()来做checkpoint,然后清空日志区域重新写入。
作为优化,所有日志条目被对齐到64字节,并利用checksum进行有效性校验(类似PMFS),因此持久化一条log entry只需要写入一条cache line和一次fence指令(如果使用valid bit则需要两次,参加PMFS)。此外,在DRAM中保存了每个U-SplitFS的log tail,并发访问时可以原子修改log tail,然后各自写自己的日志区域。
Implementation
SplitFS基于Linux 4.13内核实现,包括一个独立实现的用户态libFS,以及一个打给内核态ext4-dax的patch。
实现细节:
- 通过
LD_PRELOAD修改glibc库函数,实现分别路由数据、元数据操作到用户态、内核态的目的。 - 使用ext4-dax提供的
EXT4_IOC_MOVE_EXTioctl实现relink()。 - 为加速后续访问,打开文件时缓存其元数据,首次访问某偏移量时对附近区域建立mmap并缓存。这些缓存在
close()时不清理,只在unlink()时清理。 - 驻留在用户态地址空间中的libFS需要在fork+execve操作中被拷贝,同时维持已经打开的文件描述符。因此libFS在
fork()时随着整个地址空间一起被拷贝,并在execve()执行前将需要保存的in-memory data存储到共享内存/dev/shm,在execve()完成后恢复这些状态。 - staging file是在文件系统初始化时预先创建的,用完了会由后台线程创建新的,以此避免在critical path上创建staging file。
- 建立mmap时的大小、预创建staging file的数目、每个libFS实例log区域的大小都是可以调整的参数。
Evaluation
作者将SplitFS和ext4-dax,PMFS和NOVA进行了比较,并研究了:
- 相比ext4-dax,SplitFS对系统调用性能的影响。
- 数据操作更快,元数据操作略微变慢。
- 用户/内核态分离架构、staging file、relink等实现细节对总体性能的影响。
- SplitFS在不同一致性保证下,与对应文件系统性能的比较。
- 与其他文件系统相比,SplitFS在减小software overhead上的成效。
- SplitFS在真实应用上与其他文件系统的性能比较。
- 使用SplitFS的资源占用情况。