Optimistic crash consistency
Background
Crash Consistency
基于journal的文件系统崩溃一致性是通过保证写入操作的次序完成的。对于ext4中的data=ordered模式,只对元数据记录journal,涉及的写入操作包括写数据(\(D\)),记录元数据(\(J_M\)),提交事务(\(J_C\))和将元数据写回原位置(checkpointing, \(M\)),它们遵循的写入顺序如下: \[ D|J_M \rightarrow J_c \rightarrow M \] \(D\)和\(J_M\)的写入顺序可以颠倒(即使先写\(J_M\),由于事务没有提交,元数据不会被写回原位),除此之外需要保证另外两个写入顺序。然而Cache(即DRAM)的存在使得磁盘不能保证写入的次序和接收到请求的次序一致,因此需要使用cache flush保证写入次序。flush的使用会大大影响性能:
- flush为磁盘限制了部分写入次序,让磁盘调度器的调度选择变少,进而影响性能
- flush导致目前所有pending的write都被写入,应用不一定需要如此强的保证
- flush时会阻塞读操作并增加其latency,尤其当pending write很多的时候
- flush同时保证了写入次序和持久化,有时应用只需要保证写入次序,不需要持久化保证
Motivation
鉴于journal对性能的影响,很多文件系统的实现中干脆不开启journal,用正确性换性能。然而,人们发现即使不开启journal,crash也不一定会导致文件系统的inconsistent,作者把这种现象称为Probabilistic Crash Consistency。
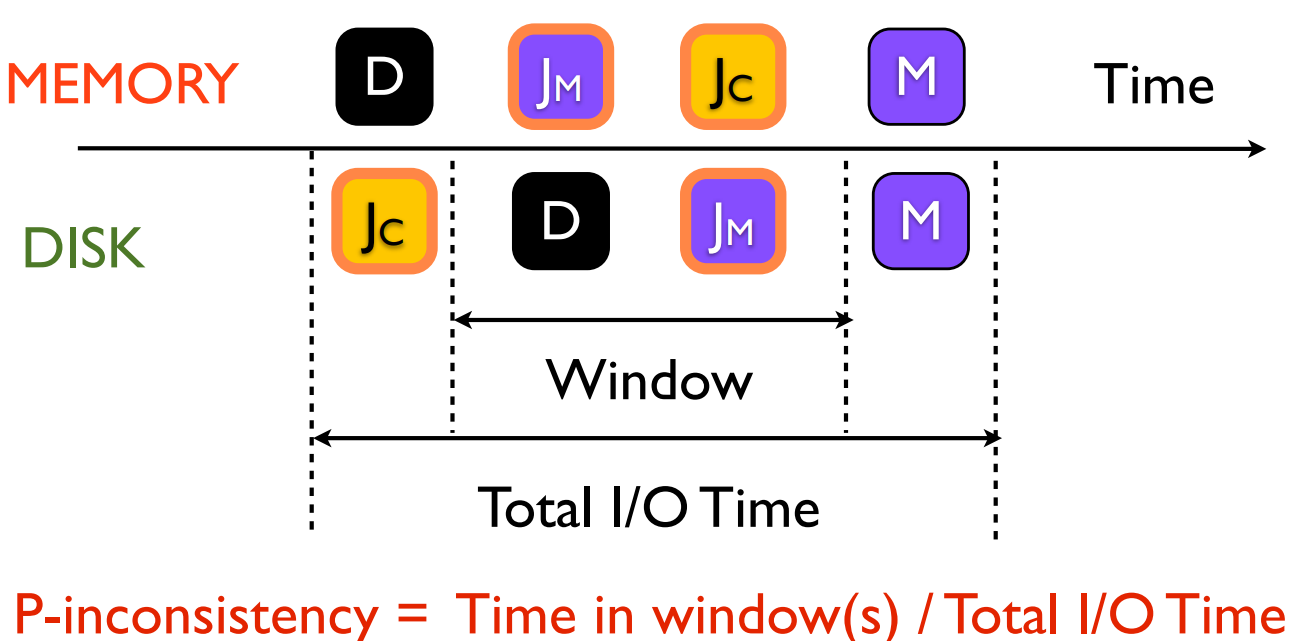 如图所示,只有在crash
window中发生的crash才会导致文件系统不一致,因此可以定量计算出\(P_{inc}\)作为inconsistency出现的概率。作者分析了影响\(P_{inc}\)的因素,它们包括:
如图所示,只有在crash
window中发生的crash才会导致文件系统不一致,因此可以定量计算出\(P_{inc}\)作为inconsistency出现的概率。作者分析了影响\(P_{inc}\)的因素,它们包括:
- 以读为主的workload不容易出现不一致,以随机写为主,或者主动调用
fsync()的workload容易出现不一致。 - 磁盘处理IO操作的queue size越小,越不容易出现不一致。当queue size为1时,不可能出现不一致。但是queue size变小也会导致性能下降。
- 数据原位置和journal区域的距离越大,越不容易出现不一致,同时性能下降。这和机械硬盘的寻道有关,间隔距离越大,\(J_c\)和\(D\)被交换的概率就越小。
基于这一观察,作者认为使用flush来保证文件系统崩溃一致性的手段是pessimistic的,因为它假设写入过程中确实会发生crash,然而这只是个概率事件。
Design
于是,作者提出了所谓的Optimistic Crash Consistency,旨在提供与pessimistic相同的一致性保证,同时性能接近probabilistic(即没有flush操作时的性能),它是通过消除两次flush来实现的,包括两个主要部分:
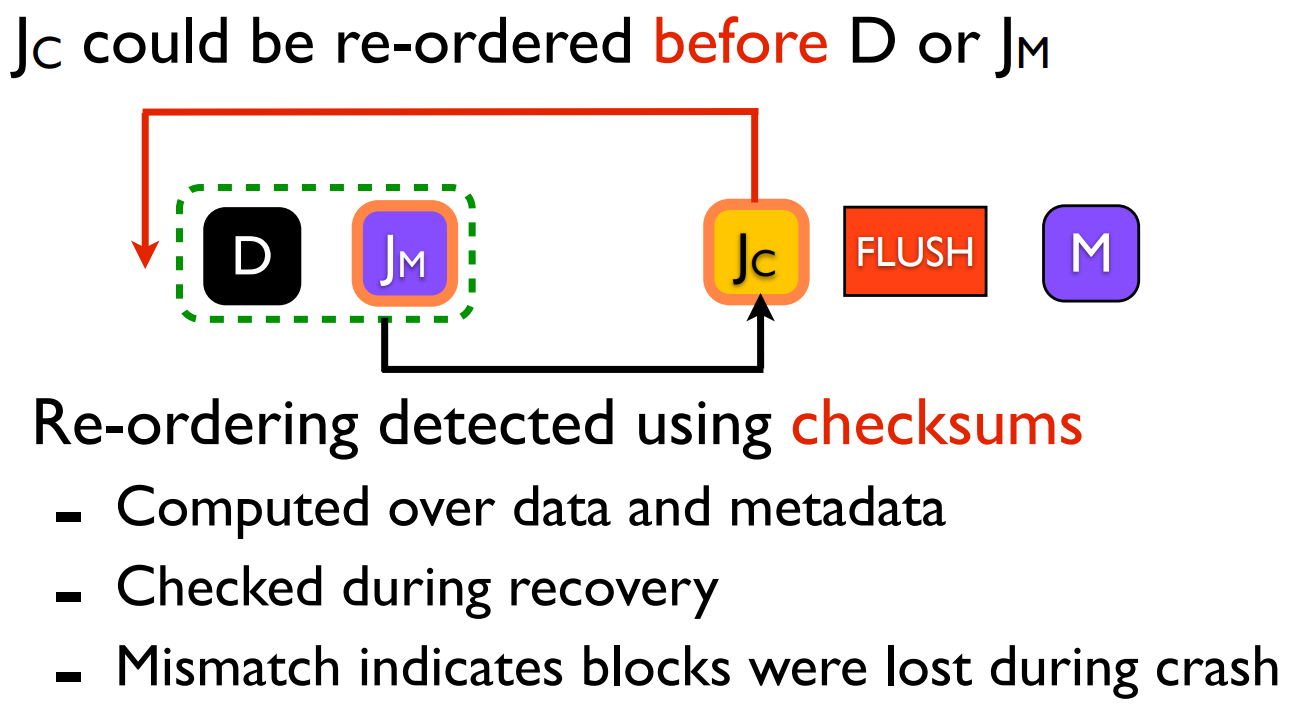
通过checksum保证\(J_c\)不会被排到\(D\)和\(J_M\)之前。checksum包括data/metadata transactional checksum,它们分别根据\(D\)和\(J_M\)的内容计算,并保存在\(J_C\)中。如果发现日志中\(J_C\)中的checksum和磁盘中\(D\)/\(J_M\)的计算结果不一致,说明\(J_C\)并没有像预期那样在\(D\)/\(J_M\)之后被持久化,而是被提到了前面,这样的commit是无效的。
通过修改硬件,为磁盘增加一个异步的Asynchronous Durability Notification,在每次完成写入的持久化之后通知应用,以此来保证\(M\)不会被排到\(D\),\(J_M\)和\(J_C\)之前。
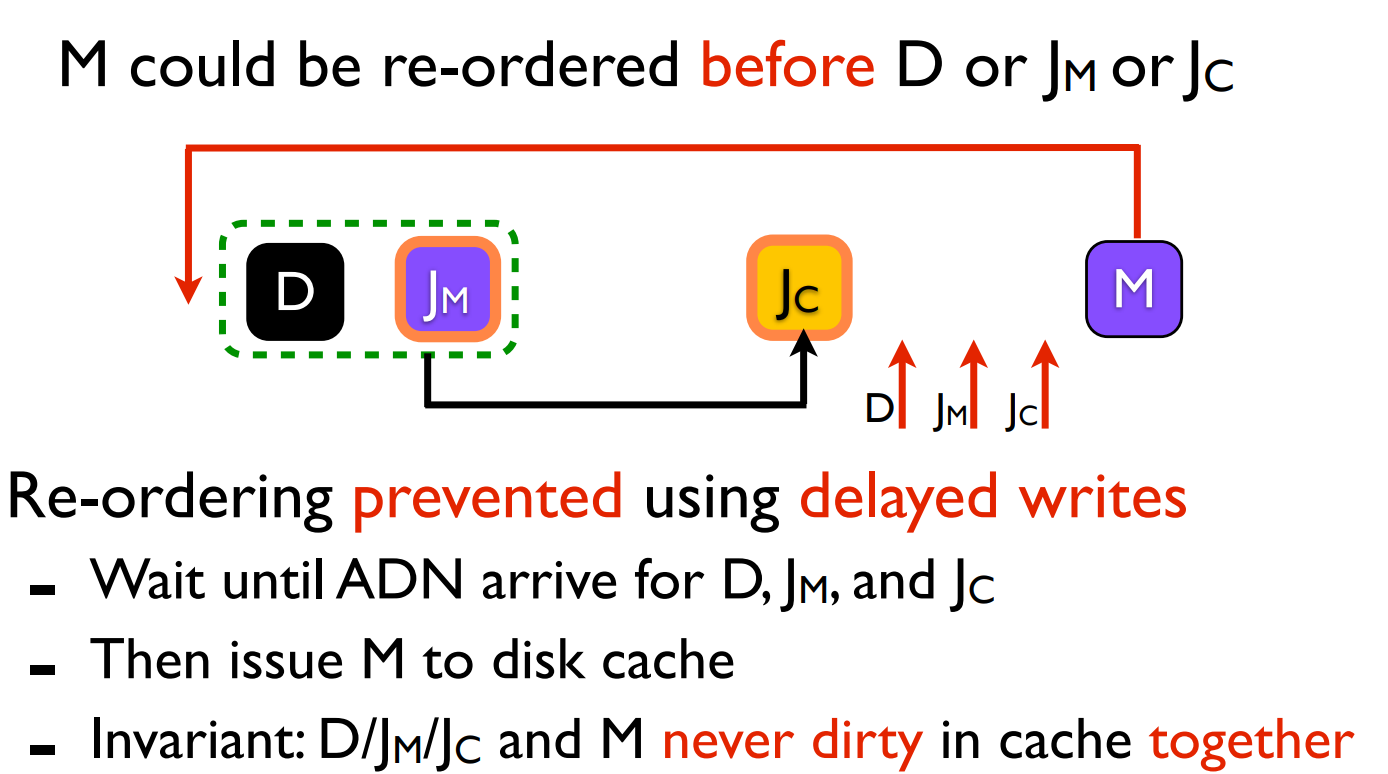
这样一来,悲观实现中所需要的两次flush操作都可以被消除。
Reuse after Notification
如果\(D\)被持久化之后,\(J_C\)被持久化之前发生了crash,恢复时事务不会被持久化。虽然\(D\)的内容已经被写入了,但是没有元数据指向它,因此不会对一致性造成影响。但是,如果D被写入的位置恰恰属于一个刚被删除的文件,就会带来安全问题,考虑以下情形:
- 操作:删除文件A,且\(M_A\)已被更新(\(J_{M'}\)),但还没有被持久化。
- 操作:写入文件B,并且恰好分配到刚被删除的文件A使用的数据块,并将文件B的数据写入。
Optimistic Consistency保证不了操作1一定在操作2之前落盘,因此一旦2被持久化但是1没有时发生了crash,恢复时虽然能通过checksum发现操作1没有完成,但是没有办法回滚操作,因为文件1原本的数据已经被覆盖了。
悲观实现不存在这个问题,因为每个事务的两次flush保证前一个事务的写入一定在后一个事务的写入之前被持久化完成。
想要解决这个问题很简单,本工作保证属于文件A的数据块在\(J_{M'}\)被持久化以后才会被分配给另一个文件。除非当文件系统接近全满时,这样做基本不会造成性能影响。
Selective Data Journalizing
在Optimistic Consistency下,文件的update操作类似于CoW,需要分配一个新页写入数据,然后修改文件元数据,带来了额外的性能负担。此时可以将要写入的数据和元数据一起记入journal,实现in-place update。
Durability vs. Consistency
本文提出了新的文件系统原语,用于解耦fsync()同时包含的ordered和durable语义。
osync()保证写入操作的次序。dsync()保证写入操作被持久化。
个人理解:osync()可以通过新加入的Asynchronous Durability
Notification实现,dsync()类似原先的fsync(),用磁盘硬件层面的flush操作实现。
Implementation
ADN需要修改现有的磁盘硬件,因此在目前的原型实现中,作者通过一个时限\(T_D\)来模拟ADN。\(T_D\)是从磁盘接收到写入请求到写入被持久化的最大时间间隔,等价于文件系统在写入请求后\(T_D\)时刻接收到了ADN。现有实现中,\(T_D\)由OptFS设置为30秒。
Selective Data Journalizing的引入带来了问题:事务1写入了数据D,计算了checksum并提交。如果此时事务2更新了数据D中的某一个块(该块被journaled,同时in-place update),会导致事务1的checksum失效。但这样的执行序列是合法的。
OptFS的解决方案是按照数据块(而非所有写入数据)的粒度计算checksum,并且允许某些块的checksum不匹配,但是被后续的事务写入这一情况。
其他详见论文。
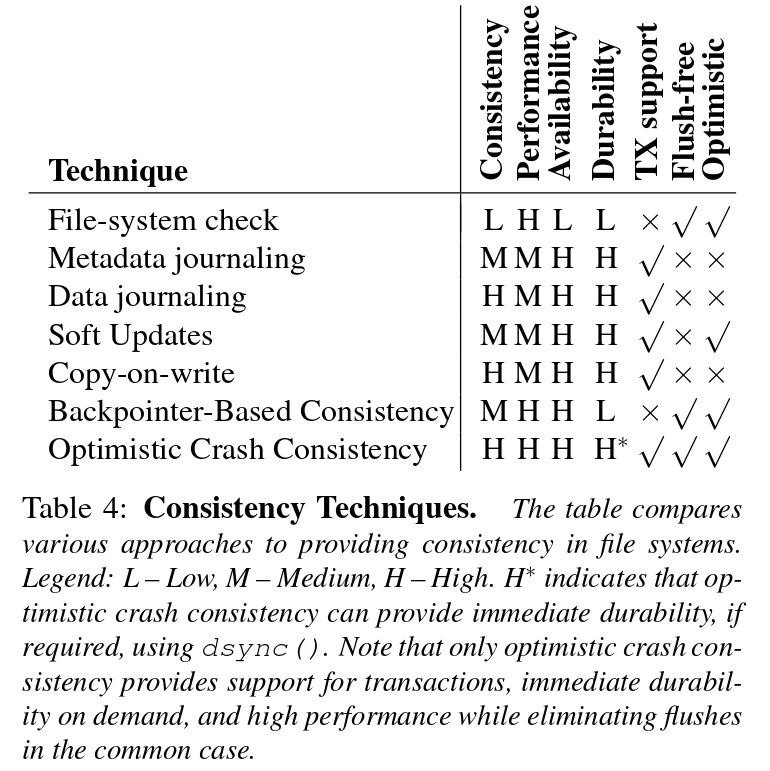
Conclusion
作者最后放了一张表,比较了各种文件系统一致性方案: