Integrated Host-SSD Mapping Table Management for Improving User Experience of Smartphones
本篇文章发表在FAST'23,作者是来自韩国首尔大学和大邱庆北科学技术院(DGIST)的 Yoona Kim 等,研究了智能手机中高效管理Host Performance Booster(HPB)的挑战和机遇, 提出了一种以用户体验(UX)为中心的HPB管理机制,在不产生额外内存压力的同时,缩短了与用户体验相关的应用程序的启动时间。
Background
使用智能手机时,影响用户体验的一大因素是应用程序的启动时间。在安卓智能手机上,大约有超过一半的应用程序启动时间被花在读取闪存(如UFS)上。 导致这一现状的一大原因是:基于Flash的存储设备存在Flash Translation Layer(FTL)层,对上层暴露的逻辑地址与实际物理地址可能不同,因此需要Logical-to-Physical(L2P)映射表存储二者之间的映射关系。 访问Flash时,必须先根据该映射表获得物理地址才能进行访问。然而,由于Flash容量的增长速度远快于SRAM容量的增长速度,移动设备的SRAM无法完全存下L2P映射表,而只能作为其缓存。 一旦需要使用未被缓存的L2P映射表项,就需要从Flash中读取,导致访问延迟大幅增加。
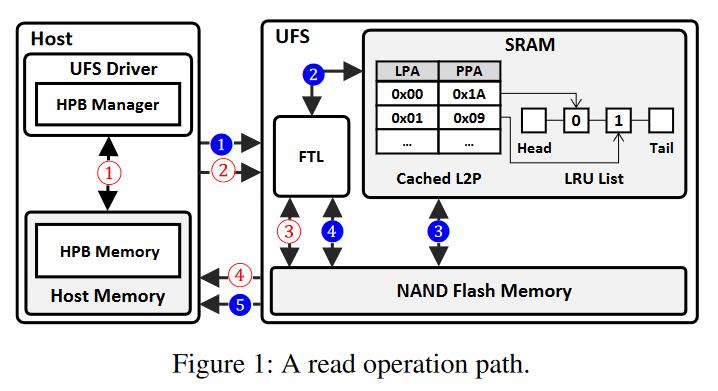
为了缓解这一问题,Host Performance Booster(HPB)技术应运而生。该技术使用一部分Host内存作为L2P映射表的缓存,以减少Flash的访问次数。 如Figure1所示,蓝色路径展示了没有使用HPB时的Flash读取路径:
- Host发起读取请求,请求的逻辑地址被传递给FTL层。
- FTL层根据逻辑地址,在SRAM中查找L2P映射表条目。
- 如果没有找到,FTL层逐出LRU链表尾部的旧条目,从Flash中读取新条目,并将其写入SRAM。
- FTL层根据L2P映射表条目获得物理地址,从Flash中读取数据。
- FTL层将数据返回给Host。
红色路径则是使用HPB时的Flash读取路径:
- Host根据请求的逻辑地址,首先试图在Host memory中的HPB里寻找L2P映射表条目。如果条目不存在,则与蓝色路径相同。
- 如果条目存在,Host获得物理地址,并和读取请求一起发送给FTL层。
- FTL层根据物理地址从Flash中读取数据。
- FTL层将数据返回给Host。
Motivation
现有的HPB技术没有从用户体验的角度进行考虑,比如:
- 用户所感知到的响应时间来自于前台应用。但现有的HPB没有区分前台/后台应用,只是根据引用计数确定需要缓存的L2P条目项。
- 如果HPB占用了过多的Host内存,可能导致应用被Low Memory Killer Daemon(LMKD)杀死,用户体验反而下降。现有实现没有动态调整HPB占用的Host内存大小。
Observation
作者开展了一系列实验,研究L2P映射表缓存和HPB对前台应用的性能影响。 实验在一台骁龙888设备上进行,通过修改Android内核收集HPB相关的统计信息,并使用Ultra-Low Latency SSD模拟UFS设备。作者研究了9个代表性应用,包括游戏、社交软件和工具软件。 > 之所以使用ULL-SSD模拟UFS设备,是因为修改UFS固件比较困难。
Impact of L2P Cache Misses on UX
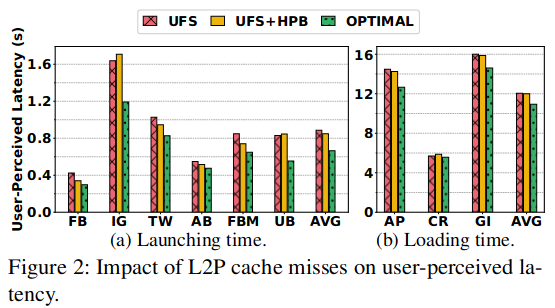
如图所示:
- UFS使用约512KB的较小空间作为L2P cache.
- UFS+HPB使用约256MB的Host内存作为L2P cache.
- Optimal是理想情况,假设UFS有充足的空间存下整个L2P映射表,因此不会出现L2P cache miss,也不需要占用Host内存。
作者的结论:
- Optimal相对UFS和UFS+HPB取得了40-50%的性能提升,说明L2P cache miss对用户感知到的时延确实有很大的影响。
- UFS+HPB相对UFS取得的性能提升并不明显,因为HPB缓存的L2P条目和前台应用无关,对改善用户感知到的时延没有帮助。
- UFS+HPB甚至在某些应用上表现不如UFS,这是因为UFS+HPB占用了Host内存,导致应用程序被LMKD杀死。
Impact of HPB Management Policy on UX
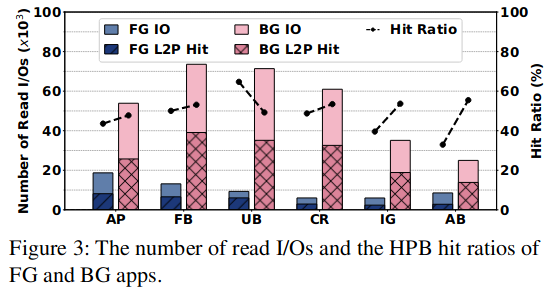
如图所示,作者观察到前台应用发出的读IO请求远少于后台应用,并且在大部分情况下前台应用的L2P cache命中率比后台应用更低。
作者解释了这一现象:一方面,现有的HPB管理策略基于引用计数确定缓存的L2P项,而后台应用的IO请求数量多,引用计数相对也更高,导致前台应用相关的L2P项更容易被逐出; 另一方面,现有HPB管理策略在内存足够时,也会定期逐出L2P项,并未考虑用户的使用习惯:用户可能使用一会前台应用,切换到另一个应用,再返回前台应用。此时前台应用的L2P项已经因为超时被逐出,导致用户感知到的时延增加。
除此之外,作者还观察到应用程序启动时会导致大量的随机IO(图见原文),它们跨越了更多的逻辑地址,因此会导致大量的L2P cache miss,并且HPB在这种情况下并不能起到很大作用。 作者认为,在内存紧张的移动设备上,可同时打开的应用程序数量是受限的,因此应用程序启动,乃至随机IO是不可避免的,HPB的策略设计应该充分考虑这一点。
Impact of HPB Size on UX
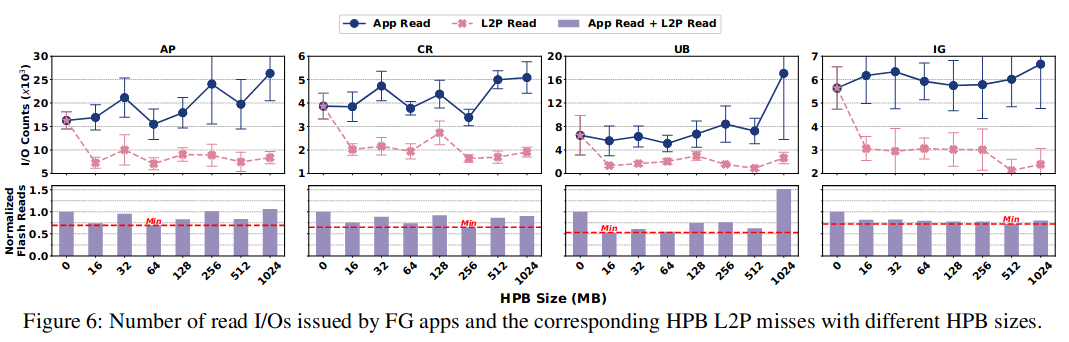
如图所示,HPB占用的内存大小会影响对Flash的IO次数:HPB越大,缓存的L2P条目越多,减少了Flash IO;但与此同时,HPB占用的内存也越多,可能导致更多的页面换出和更频繁的Flash IO,甚至导致应用被杀死。 因此,HPB大小的选择需要在两个极端之间权衡,并且在不同应用下,HPB最佳大小也不同。
作者认为,HPB的大小应该感知到当前的内存压力,并进行动态调整。这是当前基于定时器的HPB策略所做不到的。
Design & Implementation
基于以上观察,作者提出了HPBvalve,这是一种集成的Host-SSD映射管理方案。HPBvalve利用了Android中其他模块采集的信息,使得它可以低成本垂直集成到现有设备中。
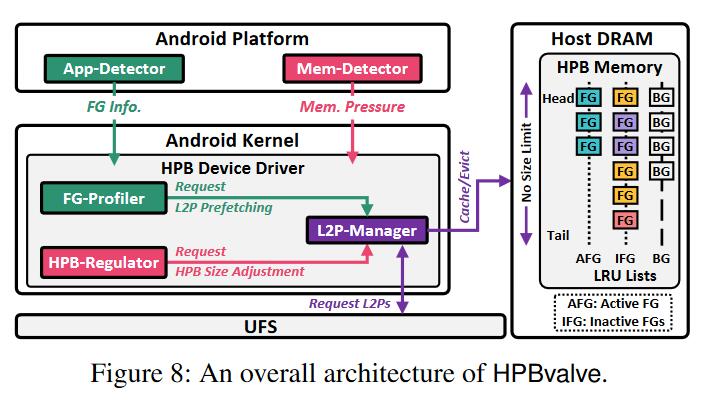
上图是HPBvalve的总体架构,它包括Android Platform层的App-Detector和Mem-Detector,以及内核中的FG-Profiler, HPB-Regulator和L2P-Manager。
FG/BG classification
HPBvalve修改了内核,让IO请求带上应用ID信息。App-Detector能感知到当前的前台应用,并传递给修改过的内核。
L2P management
L2P-Manager维护3个LRU链表:AFG(Active FG),IFG(Inactive FG)和BG,逐出时BG链表中的条目会最先被换出,其次是IFG;AFG中的条目从不被换出。
IFG代表用户先前交互的前台程序,当用户启动新的前台程序时,原来的AFG会被降级为IFG。
Caching policy of HPBvalve
Hvavle保留了基于引用计数的缓存策略。除此之外:
- 来自当前前台应用的L2P miss会导致对应L2P entry立刻被缓存进HPB。
- FG-Profiler会记录应用启动/运行时请求LBA的模式,并在用户启动新应用时根据此信息预取L2P条目。
Dynamic HPB Size Adjustment
借助于HPB-Regulator和Mem-Detector,HPBvalve可以动态调整HPB的大小,在提高L2P cache命中率和减少Host内存占用之间达到平衡。这一过程的具体流程如下图所示。
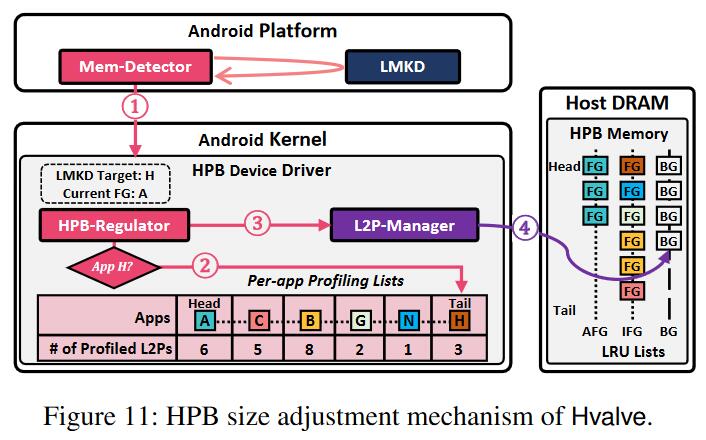
初始,HPBvalve尽可能多得使用Host内存,以期缓存最多的L2P条目,直到出现内存压力,LMKD被启动: 1. Mem-Detector将LMKD即将杀死的应用ID传递给HPB-Regulator。 2. HPB-Regulator检查该应用的重要性(即是否被最近使用,这是通过FG-Profiler收集的信息实现的),如果不重要,则终止流程,让LMKD杀死该应用。 3. 否则,HPB-Regulator告知L2P-Manager,需要释放多少内存避免该应用被LMKD杀死。 4. L2P-Manager按优先级从3个LRU链表中逐出条目,以满足Host内存需求,使该应用不被杀死。
Evaluation
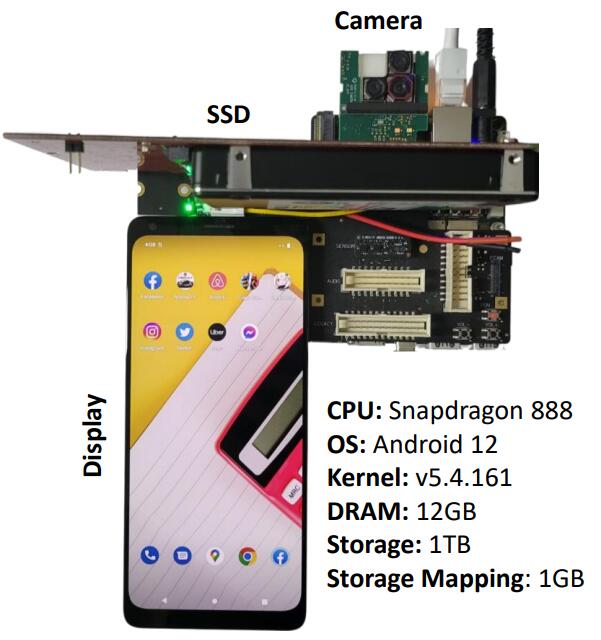
Evaluation Settings已在Observation一节描述,实验平台参数如图所示。
图中Camera是一台高速摄像头,作用是直接对显示屏采样,以精确测量应用启动时间。
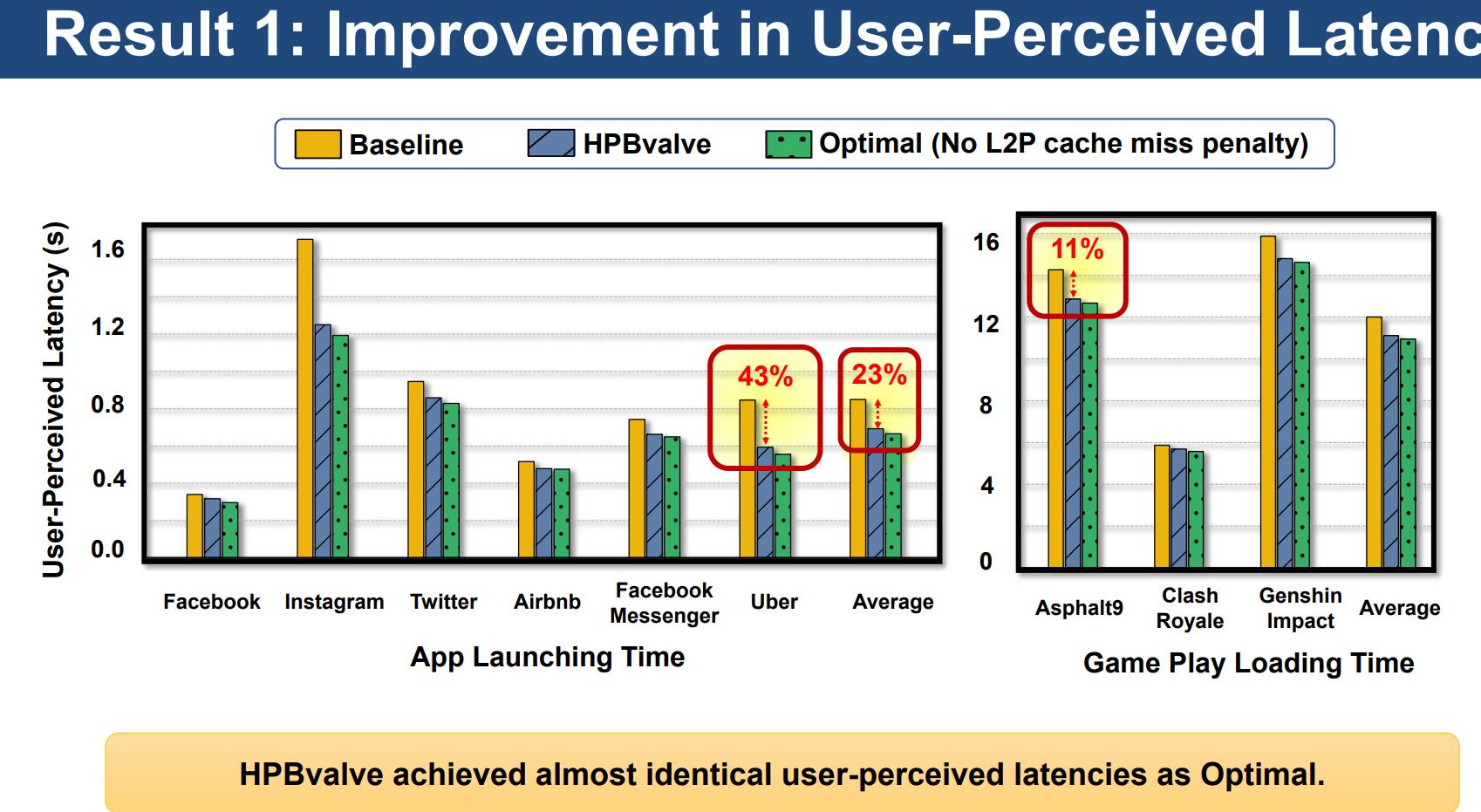 如上图,相比Baseline(UFS+HPB),HPBvalve取得了最多43%的时延下降,达到了接近Optimal的效果。这归因于HPBvalve提高了L2P缓存命中率。
如上图,相比Baseline(UFS+HPB),HPBvalve取得了最多43%的时延下降,达到了接近Optimal的效果。这归因于HPBvalve提高了L2P缓存命中率。
Optimal是假设UFS有充足的空间存下整个L2P映射表的理想情况。
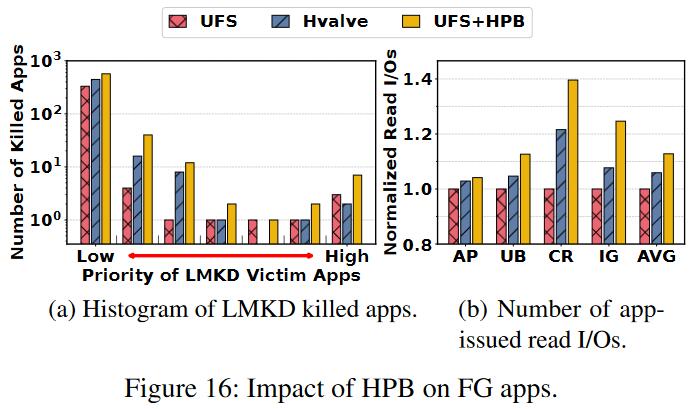 如上图,HPBvalve相较于UFS+HPB,应用更不容易因为内存不足被杀死。这是因为HPBvalve能够动态调整HPB占用的Host内存大小。
如上图,HPBvalve相较于UFS+HPB,应用更不容易因为内存不足被杀死。这是因为HPBvalve能够动态调整HPB占用的Host内存大小。
Overhead
- FG-Profiler分析应用启动模式所消耗的内存被限定为1MB,基本可以忽略不计。
- 3个LRU链表用哈希表管理,在链表之间查找并移动L2P缓存条目可以O(1)时间实现。
- HPB-Regulator会在LMKD中插入额外的逻辑,但这部分时延(约1.8ms)相对LMKD的整体时延(数百ms)影响很小。
- 使用HPBvalve不会引入额外的电量消耗,甚至相对UFS+HPB,耗电量有所降低(3.51%)。
Conclusion
本文具体分析了现有的,基于HPB的L2P条目缓存方案面临的问题和挑战,并提出了HPBvalve,一种关注用户体验的改进解决方案。 该方案区分了前台和后台应用,并且能够根据Host内存压力动态调整HPB的内存占用。 实验证明,HPBvalve能够有效地减少应用启动/切换时的时延,提高了用户体验。