EROFS: A Compression-friendly Readonly File System for Resource-scarce Devices

本文描述了EROFS,这是一种只读压缩文件系统,已经合入Linux主线,并在Android中有相当大规模的应用。该工作由华为和IPADS合作完成,第一作者高翔现于(2023.5)阿里工作,仍然在积极维护EROFS。
Background
问题:安卓系统占用的空间与日俱增,挤占了智能手机上的存储空间,对于低端设备尤甚。
一种优化方式是使用带压缩支持的文件系统(例如btrfs),它们在写入/读取数据时会透明地对数据进行压缩/解压缩,以节约存储空间。然而作者声称,它们不适合在资源受限的智能手机上使用,因为(解)压缩会消耗计算资源,而btrfs无法同时满足压缩率和资源消耗两方面的需求。
考虑到系统分区存储只读数据,如果使用仅支持只读的文件系统,可以简化掉修改文件的逻辑和数据结构以提升性能。现有的系统分区往往使用只读挂载的ext4,没有利用这一优势;此外,ext4也不支持压缩,没有充分节约存储空间。
Motivation
现有一些只读压缩文件系统的工作,例如Squashfs。它支持多种压缩算法和多种压缩输入大小,同时压缩数据和元数据。然而,作者将Squashfs用于Android只读分区,发现启动相机应用需要数十秒,性能无法接受。
作者分析了Squashfs表现不佳的原因:
I/O放大。作者使用FIO从Squashfs中读取16MB的数据。如图所示,在使用128KB的压缩输入大小时,Squashfs尽管在顺序读时减少了I/O大小,但是在随机读(165.27MB)和跳跃读(203.91MB)时都经历了一个数量级的I/O放大。
跳跃读:从每个128KB块中读取前4KB。这是一个最坏情况,因为每个128KB块都必须被解压才能读取。
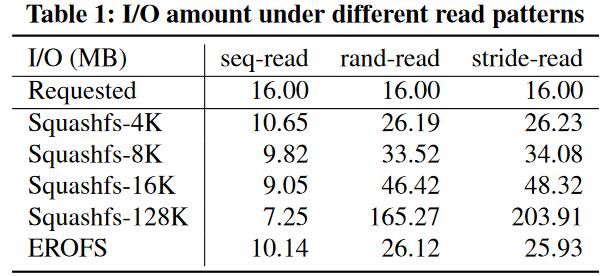
额外的内存消耗。作者指出,在Squashfs中顺序读取1GB数据后实际消耗了1.35GB的内存。这可能导致页面换出,影响系统其它部分的性能。
接着,作者分析了Squashfs的设计,并指出导致这些问题的原因:
- 压缩输入大小是固定的。Squashfs将固定大小(可配置,如128KB)的输入进行压缩,生成长度不固定的压缩数据,然后将压缩后的数据紧凑存储。这样的设计会造成I/O放大,如下图所示,压缩数据分布在3个物理块中,因此读取1字节的原始数据需要读入3个物理块进行解压。减少压缩输入大小(如4KB)可以改善这个问题,但同时也会导致压缩率下降和CPU使用率上升。
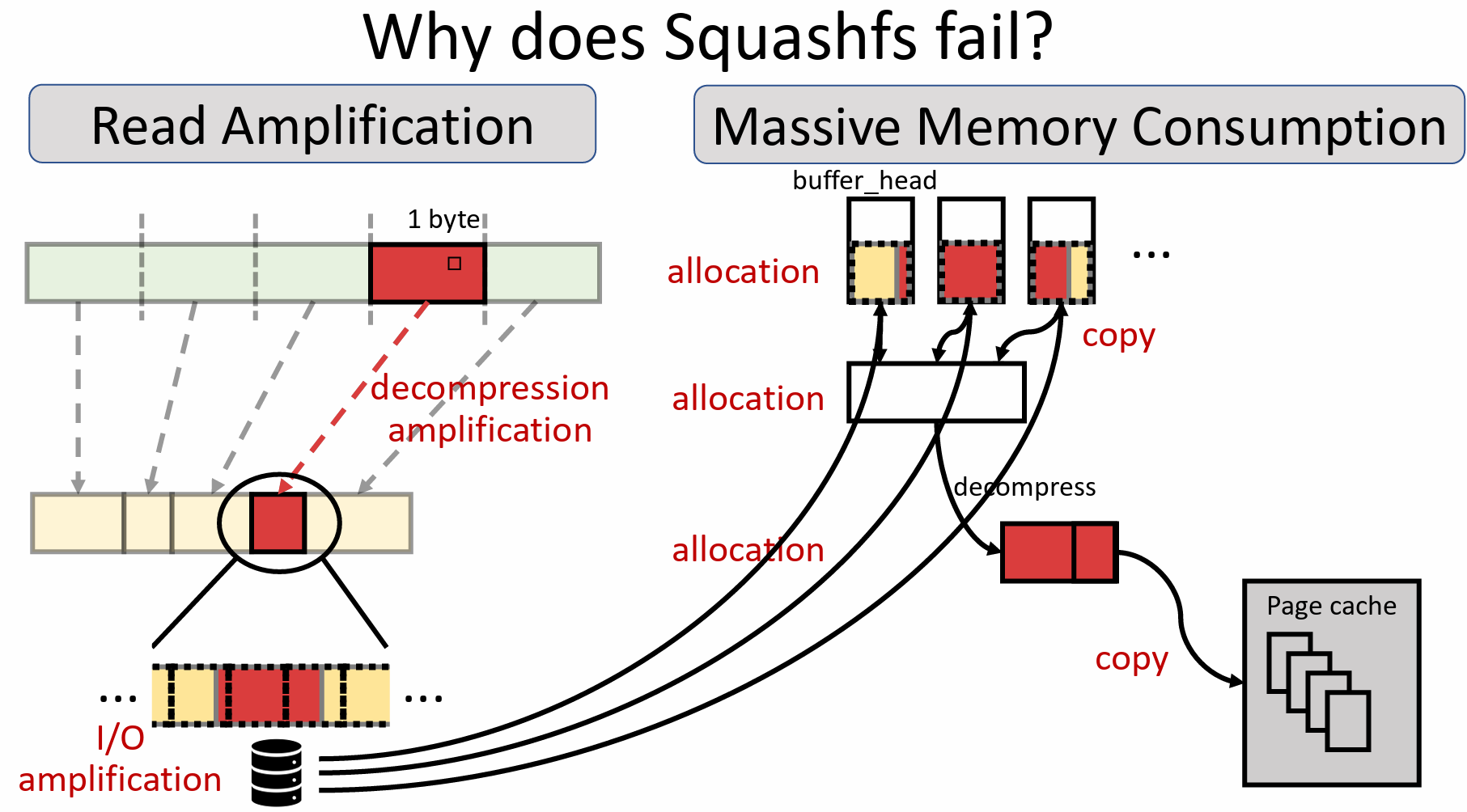
- 频繁的数据移动导致了较大的内存占用。如图所示,为了处理文件读取请求,Squashfs需要:
- 查找元数据,获知压缩块的数量。
- 为每个压缩块分配缓存并读入数据。
- 这些缓存的虚拟地址不连续,不满足解压的需求,因此需要将待解压数据拷贝到一个连续缓冲区中。
- 解压缩,输出被存入一个输出缓冲区。
- 从输出缓冲区将需要的原始数据拷贝到文件对应的page cache。
这个过程涉及大量内存分配和多次内存拷贝,使得内存访问成为压缩/解压过程中的瓶颈。
因此,一种好的只读压缩文件系统应该能够在保证压缩率的前提下降低I/O放大,在保证解压性能的前提下降低内存占用。
Design
固定输出大小
EROFS的压缩输出大小是固定的(4KB)。压缩时,EROFS将不定长的输入数据压缩为固定大小的压缩数据块。其优点是:
Q:这个压缩过程具体是怎么工作的?
压缩率高,因为相较于固定输入大小,压缩时可以尽可能地消耗输入数据直到满足输出大小限制。
- 减少读放大,因为压缩数据块一定是对齐到块大小的,解压时不需要读取不必要的压缩数据。
固定的压缩输出大小支持就地解压。这也许是因为块对齐的压缩块可以直接被放到page cache中,然后就地解压并返回原始数据。如果不对齐,会把不需要的脏数据带进page cache。
I/O缓存策略
EROFS支持两种读取策略,分别称为cached I/O和in-place I/O:
- cached I/O:如果一个压缩数据块只需要被部分解压就能满足读取请求(例如只读取了几个字节),它会被缓存在erofs中一个专用inode的page cache中,以便需要解压同一个块的后续读取请求复用。
- in-place I/O:如果一个压缩数据块已经被全部解压,它就不需要被缓存了,因为解压后的数据已经在page cache中。这种情况下该压缩块不会被缓存在内存中。在这种情况下,压缩数据块被直接存放在VFS分配的page cache中(这也是应该存放解压后的文件数据的地方),因此称为in-place I/O。
解压方式
EROFS支持多种解压方式,其中基于vmap解压是通用情况,其他方式都是不同场景下的优化。
如图所示假设数据块D0-D8被压缩为C0-C1:
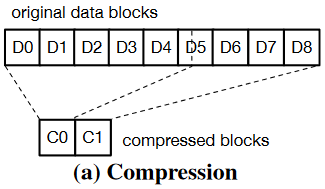
使用vmap:假设需要读取数据块D3和D4。
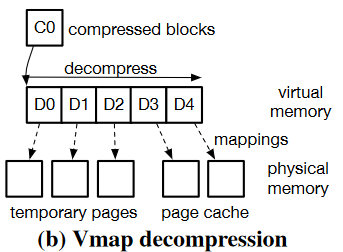
- 获取解压后的数据大小并分配一段足够大的虚拟地址空间。在上例中,由于不需要D5中的数据,解压时获得D0-D4的数据后就能停止,不需要完整解压C0。
- 根据该大小分配额外的物理页。由于需要读取D3和D4中的数据,它们可以直接复用VFS为page cache分配的物理页,只需要额外分配D0-D2即可。
- 对于in-place I/O,需要把C0(位于应存放解压后数据的page cache中)拷贝到另一个per-cpu缓存中,防止解压后的数据覆写未解压的压缩数据(该过程可优化)
- 解压C0,然后回收D0-D2对应的物理页。需要读取的数据已经进入了page cache。
使用per-cpu buffer。EROFS为每个CPU预先分配4个页面的缓存,用于满足解压后数据大小不超过4页的读取请求,然后将需要的数据拷贝到page cache。这样做省去了vmap中分配和回收临时页面的开销。
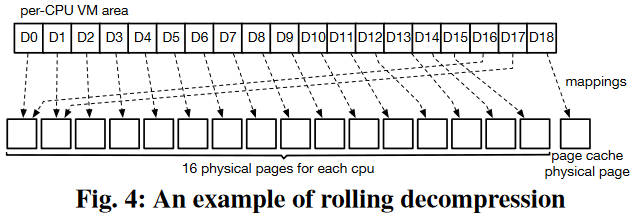
滚动解压。由于EROFS使用的lz4算法最多需要当前位置之前64KB的数据,解压时对于读取请求不需要的数据,维护一个大小为16页的滑动窗口即可。如图所示,EROFS为每个CPU预先分配16个物理页和足够大(典型值:256个物理页)的虚拟地址空间。对不需要的数据,让虚拟页复用这16个物理页;对需要的数据,让虚拟页映射到page cache物理页。
使用该虚拟地址空间进行解压,可以在保证lz4算法正确性、没有解压后大小限制的同时,省去页面分配和回收的开销。
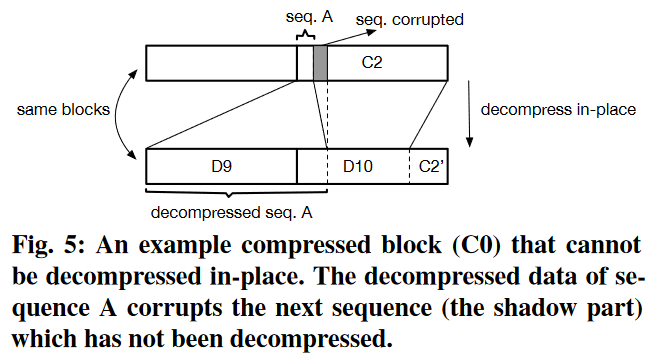
就地解压。如图所示,在in-place I/O中之所以要将压缩页拷贝走,是因为解压后的数据可能覆盖尚未解压的数据,导致错误。作者观察到99.6%的压缩页都不存在这种情况。因此,EROFS在压缩时模拟解压过程,并标记该压缩页是否可以就地解压。如果可以,EROFS可以直接就地解压被读取到page cache中的压缩页,进一步减少了内存拷贝。
Implementation
本文实现部分提及了两个版本的EROFS,在EMUI上实际部署的版本需要更严苛的测试,因此特性没有最新版丰富。
内存布局
如图所示,EROFS的superblock位于image开头。文件的元数据和数据连续存储在一起,但只有数据部分会被压缩。文件inode号可以根据偏移量计算出来,以便于快速寻址到inode。
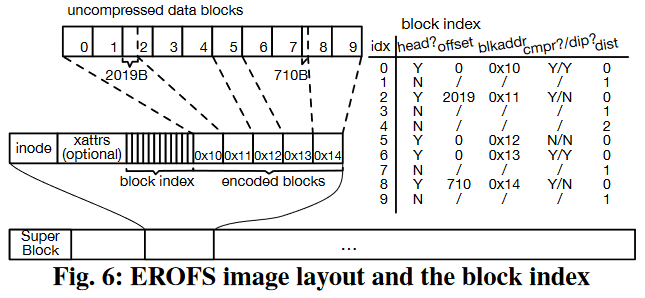
每个文件都有一个block index数组,索引所有的原始数据块。称被压缩到同一压缩块的原始数据为一组。各字段含义如下表所示:
| 字段 | 含义 |
|---|---|
| head | 是否为一组原始数据中的第一个块 |
| offset | 该组原始数据的起始位置在块中的偏移量 |
| blkaddr | 该组原始数据对应的压缩块的下标 |
| cmpr | 该组原始数据是否被压缩(如果压缩后大小超过原始大小,EROFS会直接存储原始数据) |
| dip | 该组原始数据是否可以就地解压 |
| dist | 当前数据块离该组原始数据中起始块的距离 |
解压策略
文中描述的EROFS的解压策略:
如果解压后原始数据大小小于块大小,使用per-cpu buffer进行解压。
不能就地解压,因为原始数据无法完全覆盖压缩数据块,会带来脏数据。
否则,如果该压缩块可以被就地解压,使用就地解压策略。
否则,如果解压后原始数据大小小于滚动解压中分配的per-cpu虚拟地址空间大小,使用滚动解压策略。
否则,fall back到基于vmap的解压策略。
优化点
Index memory optimization,看起来是说如果EROFS把数百个页压缩到一个页中,读取时需要在内存中维护几百个指针,来追踪这几百个页要被解压到哪里。该优化利用VFS分配的page cache中的空闲页来暂存这些指针,以节约内存。
几百个指针好像也占不了多少空间?
Scheduling optimization,解压需要时间,不适合在(读请求的)中断上下文中完成。Btrfs有专用的解压线程负责解压读取到内存中的压缩数据,然后唤醒reader线程。为了减少调度开销,EROFS没有解压线程,就是由reader线程负责解压数据并直接读取。
Cohort optimization,多个请求如果需要解压同一个压缩块,不需要重复进行。一个线程完成解压后,其他线程直接读取解压后的原始数据即可。
Image patching,只读文件系统在系统升级时仍然有一些更改需求。EROFS为这种情况提供了一些有限的支持:将修改部分的新数据放在镜像末尾,不改动原始数据,读取的时候用新数据覆盖解压后的旧数据。
这应该只是一种适用于极少量修改的临时方案。
Comments
- 现版本(Linux v6.3)中的EROFS已经和论文中描述的版本有着很大变化。
- 虽然文章中没有明确说明,但是一些设计选择表明,压缩算法有着如下的性质:
待解压的数据必须位于一段连续(虚拟)内存中。
单次压缩输入数据越多,压缩率越高。
解压时,位于读取位置前的所有原始数据必须被全部解压出来,不能直接从压缩块中间某个位置开始解压。