Effective C++ Notes (1)
Introduction
非必要时,总是使用
explicit修饰构造函数,防止预期以外的隐式类型转换。=可能触发拷贝构造函数和拷贝赋值,取决于有没有新对象产生。1
2
3
4Widget w1;
Widget w2(w1); // 拷贝构造
w1 = w2; //拷贝赋值
Widget w3 = w2; // 拷贝构造
Accustoming yourself to c++
Item 1: View C++ as a federation of languages
C++语言可以看作多个次语言的组合,它们是:
- C,基础部分
- OOP C++,或者称为C with Classes,在C基础上加入了OOP设施(类,封装,继承等等)
- Template C++,泛型编程,甚至模板元编程。
- STL,涉及container, iterator, algorithm和function object。
Item 2: Prefer consts, enums, and inline to #define
使用const定义常变量
使用预处理器#define定义常变量存在问题:
- 定义的符号不会进入符号表,给编译信息/调试带来困难。
- 如果变量本身占用空间较大(如
double类型),定义出来的变量在源码中多次出现,让代码体积变大。 - 不符合c++的风格。
使用const定义常变量是更合适的选择,注意:
- 定义常字符串时,最好使用
std::string,如const std::string name = "Tom"。如果使用C风格的char*,指针本身和指向的字符串都应该是const,即const char* const name = "Tom"。
如果要让一个常量的作用域被限制在某个class内,我们会为该class定义静态常量成员。
1 | class A { |
这里对A::i的初始化只是声明(declaration),而非定义(definition)。
一个变量只能被定义一次,如果这里是定义,定义了
class A的头文件就不能被多个源码文件#include了。
为什么可以初始化一个声明呢?C++标准(9.4.2节)中如是说:
If a non-volatile const static data member is of integral or enumeration type, its declaration in the class definition can specify a brace-or-equal-initializer in which every initializer-clause that is an assignment expression is a constant expression (5.20). A static data member of literal type can be declared in the class definition with the constexpr specifier; if so, its declaration shall specify a brace-or-equal-initializer in which every initializer-clause that is an assignment-expression is a constant expression. [Note: In both these cases, the member may appear in constant expressions. —end note] The member shall still be defined in a namespace scope if it is odr-used (3.2) in the program and the namespace scope definition shall not contain an initializer.
可以看出这是一个特例,只有integral和enum类型的静态常量成员可以通过这种方式,对声明进行初始化。此时,使用这个常量成员相当于直接做了常量替换(就好像是#define出来的一样)。
#define无法控制变量的作用域,也无法提供访问控制(如声明一个private常量)。
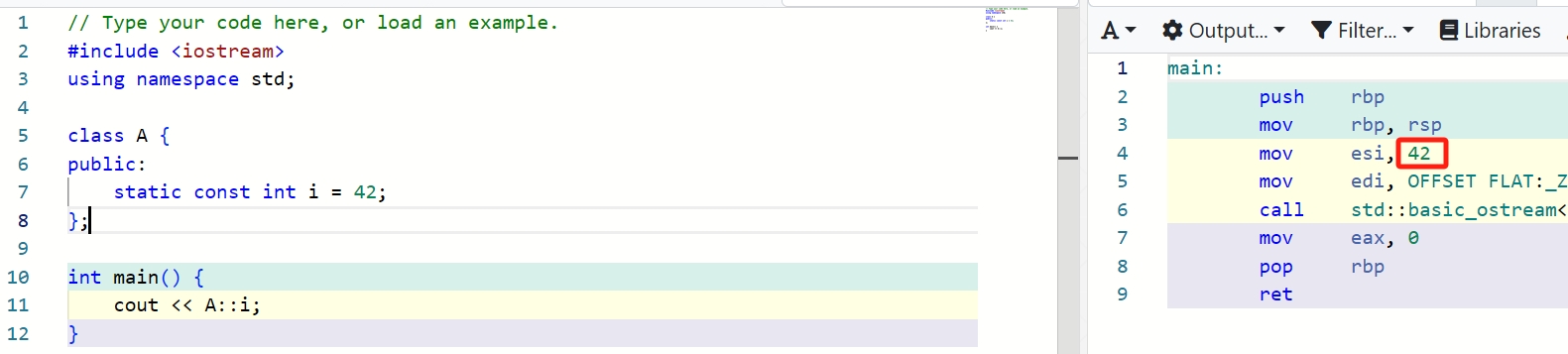
因此,这个静态常量成员也不能被取地址,除非对其进行定义。这个定义不能再次对该变量进行初始化。
1 | class A { |
如果静态常量成员不是integral或者enum类型,不能使用上述方式初始化。
1 | class A { |
而必须先声明再定义:
1 | class A { |
或者使用constexpr关键字:
1 | class A { |
旧编译器可能不支持对静态常量成员的声明进行初始化,此时可以:
1 | class A { |
这一用法被称为enum hack,这里的i是一个不能被取地址的右值。古老的代码可能会这么写。
参考:
使用内联模板函数代替#define定义宏
通过#define定义出来的宏有许多问题:
1 |
必须记得给实参加小括号,否则用一个表达式调用宏可能会出现运算顺序的问题。
即使加了小括号,使用表达式调用宏仍然很tricky。
1
2
3
4
5int a = 5, b = 0;
CALL_WITH_MAX(++a, b);
// now a == 7
CALL_WITH_MAX(++a, b + 10);
// now a == 8同样使用
++a调用宏,a可能被递增一次或两次,这取决于另一个操作符。
为了规避以上问题,最好用内联模板函数代替宏的作用:
1 | template<typename T> |
Item 3: Use const whenever possible
常量指针/迭代器:
1 | // 指向常量 |
给函数返回值加上:const,可以防止将比较误作为赋值
1 | const Rational operator* (const Rational& r, const Rational& l); |
知乎用户Mick235711指出这一条是不合理的,该背锅的是pre-C++11没有提供ref-qualifier,没有办法在语法层面阻止给一个右值赋值。
在C++11之后,我们可以限定只有左值能调用赋值运算符:
1 | S& S::operator=(const S& other) & {/* ... */} // copy assignment |
而如果像作者说的那样给返回值加const,可能会影响返回值优化(编译器认为返回值是不能修改的常量),从而影响性能。
const成员函数
仅const属性不同的成员函数,可以被重载:
1 | class A { |
可以让non-const成员函数调用const成员函数来减少代码冗余:
- 用
static_cast把this转成const来调用const成员函数。 - 用
const_cast去掉返回值的const修饰符。
1 | class A { |
bitwise constness v.s. logical constness
Bitwise constness(或physical constness)指const成员函数不能修改const对象中的任何成员变量,这也是编译器遵循的规则。
然而,有时程序希望const成员函数只是逻辑上的,不强求不修改成员变量,称为logical constness:
1 | class A { |
如上,getLength()毫无疑问应该是const函数,但它却需要修改length和cached成员变量,因而无法通过编译。
解决方法是将length和cached声明为mutable。
Item 4: Make sure that objects are initialized before they're used
在构造函数中,使用初始化列表(调用成员的构造函数)比在函数体中直接赋值(调用成员的默认构造函数+拷贝赋值运算符)更好。
- 如果成员是内置类型,两个方式其实没区别,但为了保持一致最好也用初始化列表。
- 成员初始化顺序是成员变量的声明顺序,而与初始化列表中指定的顺序无关。因此代码中两个顺序最好一致,避免困惑。
不同编译单元(如两个源码文件)中静态变量的初始化顺序是不确定的,不能对这一顺序做假设。此时可以用函数包一层local static变量并返回(类似于单例)。
1
2
3
4
5
6
7
8// 另一个文件通过extern使用该变量时,不能保证已经完成初始化
A globalA;
// 好的写法
A& getA() {
static A a;
return a;
}
补充:
non-local static对象(非内置类型)的构造函数何时被调用?
https://stackoverflow.com/questions/1271248/c-when-and-how-are-c-global-static-constructors-called
local static对象如何做到只被构造一次?
答:编译器会生成判断语句进入不同的执行流,同时还要保证这个构造过程是线程安全的。
https://stackoverflow.com/questions/23829389/does-a-function-local-static-variable-automatically-incur-a-branch
Ctors, Dtors and Assignment Operators
Item 5: Know what functions C++ silently writes and calls
编译器可能会为类生成下列成员函数:
- (默认)构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值运算符
- 移动构造函数(since C++11)
- 移动赋值运算符(since C++11)
一般来说,用户没有定义却使用了上述函数时,编译器会给出默认定义。每个函数也存在自己的特例情况,会让编译器不生成默认定义,例如:
1 | class NameObject { |
编译器不会为NameObject生成默认赋值运算符,因为引用nameValue不能被重新绑定,常量objectValue不能被修改。
Item 6: Explicitly disallow the use of compiler-generated functions you do not want
鉴于编译器会生成默认成员函数,如果这不是期望的行为,我们需要阻止它。
在C++11之前,这通过将不想要的函数声明为private来完成。这样一来,调用这些函数会导致编译错误。
然而,如果在类的成员函数(或友元函数)里调用不想要的函数,这并不违背private的访问控制,编译可以通过,直到链接时才因为符号未定义导致错误。
如果希望这种情况下也出现编译错误而非链接错误,可以定义:
1 | class Uncopyable { |
通过继承Uncopyable禁用拷贝构造函数和拷贝赋值运算符:
1 | class myStruct: private Uncopyable { |
这些奇技淫巧在C++11以后可以用=delete取代。
Item 7: Declare destructors virtual in polymorphic base classes
多态基类的析构函数应该被声明为虚函数以触发动态绑定,否则使用基类指针指向派生类对象时,析构函数会绑定到基类的版本,造成派生类部分的成员未被析构。
- 多态基类的典型特征是有虚函数的类。如果一个类没有虚函数,它通常不会被当作一个用作多态目的的基类。然而,这并不代表这个类不能被继承,例如Item
6中的
class Uncopyable。 - 如果将一个非多态基类的析构函数声明为虚函数,可能会导致非预期的错误行为。例如,这样做为该类引入了不必要的虚函数表,导致类的大小膨胀。
标准库中的许多类和容器(std::string
std::vector
std::set等)都没有虚函数,更没有虚析构函数,因此最好不要继承它们。
如果我们想让一个多态基类成为抽象类,可以选择将它的析构函数声明为纯虚函数。由于任何一个派生类都会有(用户定义或编译器生成的)析构函数,也就一定会重写基类的纯虚析构函数,这样做不需要引入其他的代码修改,除了:必须为这个纯虚函数给出定义,以供派生类对象在析构时调用,否则会导致链接错误。
派生类将析构函数声明为
=delete会怎么样?编译错误,deleted function cannot override a non-deleted function.
1 | class Base |
为了定义抽象类,为什么要声明纯虚析构函数?直接将任意一个虚函数定义为纯虚函数不行吗?
答:假如一个基类有虚函数
foo()和bar(),我们期望的行为可能是某些派生类覆盖foo(),另一些派生类覆盖bar()。将foo()和bar()中任何一个声明为纯虚函数都会强制要求所有派生类覆盖它,不符合期望的行为。为什么可以定义一个纯虚函数?
答:纯虚函数只是要求派生类必须重写它,不代表基类不能给出定义,这是两个正交的问题。事实上,派生类可以在重写纯虚函数时仅仅调用基类的版本。
Item 8: Prevent exceptions from leaving destructors
在C++中,栈展开(stack unwinding)指的是被抛出的异常会在调用栈中向上传递,直到被catch住为止。期间所遇到的,没能捕捉住异常的函数的生命周期结束,其中的局部变量会被析构。
1 | class A { |
由于fun1()抛出的异常直到fun3()才被捕获,fun1()和func2()的生命周期在异常被抛出后结束,以上代码会输出:
1 | ~A() is called. |
如果析构函数本身会抛出异常,可能会导致非预期的结果,例如:
1 | class Widget { |
当try代码块的生命周期结束,第一个Widget被销毁时,抛出第一个异常。此时其他99个Widget对象也需要被析构,每个都会抛出异常。C++不允许同时处理多个异常,这会导致未定义行为。
在C++11中,析构函数被默认标记为noexcept,如果抛出异常会触发std::terminate()。如果执意要在析构函数中抛异常,需要用noexcept(false)标记析构函数。
1 | class Widget { |
既然析构函数中最好不要抛出异常,如果析构函数需要执行一个可能会抛出异常的动作,应该怎么做呢?
- 直接在析构函数里处理异常,可以直接吞掉,或者abort掉程序。
- 把抛出异常的动作挪到析构函数外的某个函数中,类的用户有义务在析构前调用该函数。
Item 9: Never call virtual functions during construction or destruction
在构造函数和析构函数中都不能调用虚函数:
1 | class A { |
输出将会是:
1 | foo() from A |
B()会调用基类构造函数A(),当A()被调用时,对象B的初始化还没有完成,此时这个构造中的对象被视为一个类型A的对象,因此虚函数动态绑定到类型A的版本上。
析构函数同理。对派生类B的对象,在执行基类析构函数时,派生类部分已经被析构,析构中的对象被视为一个基类对象,因此基类构造函数中对虚函数的调用会绑定到基类版本上。
Item 10: Have assignment operators return a reference to *this
赋值操作符= += -=
等应该返回一个指向*this的引用,使得连锁赋值合法。
1 | class A { |
Item 11: Handle assignment to self in operator=
拷贝/移动赋值运算符应该考虑到变量被赋值给自己时的情形:
1 | class A { |
当自我赋值发生时,第15行将会use after free。
解决方法是判断左右对象的地址是否相等,以此鉴别自我赋值:
1 | A& operator= (const A& rhs) { |
但是,这样做不能保证exception
safety,如果第6行在成员变量对象的构造函数中抛出异常,s会指向一块无效地址。
可以先构造对象,再移动指针来做到异常安全:
1 | A& operator= (const A& rhs) { |
哪怕去掉自赋值判断,这段代码也是正确的,只是会重复构建一个相同的std::string。
Item 12: Copy all parts of an object
- 拷贝构造函数/拷贝赋值运算符应该复制对象的每一个成员,包括派生类成员和基类成员(通过调用基类对应函数)。
- 拷贝构造函数和拷贝赋值运算符不应该互相调用。如果它们之间有相似逻辑,可以抽出一个private函数来复用代码。
Resource Management
Item 13: Use objects to manage resources
调用者常常需要负责释放占有的资源:
1 | Investment *createInvestment(); |
createInvestment返回一个裸指针,这是一件危险的事,需要确保在代码的每个退出路径上资源都被正确释放。但...中可能有early
return,goto甚至抛异常,造成心智负担。
RAII(Resource Acquisition Is Initialization)原则指引我们用对象管理资源,利用析构函数在离开作用域时被自动调用的语言特性确保资源不发生泄漏。
1 | void f() |
RAII指的是资源Investment一被取得,就立刻被用于资源管理对象std::shared_ptr<Investment>的初始化。
std::auto_ptr为什么被删除了?答:
auto_ptr的(拷贝)复制语义是转移所有权,不能用在标准库容器里。例如:
2
3
4
5
6
7
8
9
10
11
12
std::vector<std::auto_ptr<int>> v(3);
v[0] = std::auto_ptr<int>(new int(11));
v[1] = std::auto_ptr<int>(new int(45));
v[2] = std::auto_ptr<int>(new int(14));
std::auto_ptr<int> p = v[0];
cout << *p << endl;
cout << *v[0] << endl;
}这段代码可以通过编译,执行第8行之后,v[0]就成为了一个空悬指针,第11行解引用会出现段错误。
有了移动语义之后,
std::auto_ptr的替代品std::unique_ptr可以只提供移动构造/移动赋值,使上面的代码无法通过编译。
Item 14: Think carefully about copying behavior in resource-managing classes
上例中,智能指针被用于RAII目的,管理的资源是堆上分配的对象。有时,需要管理的资源是其他类型,比如互斥锁。此时资源的获取和释放动作不再是分配/释放内存(智能指针的默认行为),而是lock()和unlock()。
为了对这类资源进行RAII,一种选择是构建自己的资源管理类:
1 | // Resource class |
这个例子中的资源是myMutex,通过myLock进行资源管理。用户通过定义一个block,并在block开始处创建一个myLock对象来使用互斥锁:
1 | myMutex mutex; |
但是,我们不能忘记处理资源管理对象myLock的拷贝构造/拷贝赋值行为。针对不同的场景,可以:
禁止拷贝(本例,拷贝一个Lock是不合理的)
引用计数
可以通过将指向资源的指针改成
std::shared_ptr,并指定一个deleter来实现,例如:1
2
3
4
5
6
7
8class myLock {
public:
myLock(myMutex *m): _m(m, [](myMutex *m) { m->unlock(); }) {
_m.get()->lock();
}
private:
std::shared_ptr<myMutex> _m;
};连着管理对象一起复制,即深拷贝(例如拷贝一个
std::string也会复制其管理的堆上字符串)移交对象所有权(C++11以后由移动语义处理)
Item 15: Provide access to raw resources in resource-managing classes
尽管有了资源管理类,我们仍然难以避免和只能处理原始资源(即裸指针)的API打交道。因此,资源管理类需要提供能够访问到原始资源的方式。
对于智能指针,我们可以通过重载的operator->和operator*,或者通过get()函数直接解引用/使用底层裸指针。
对于自定义的资源管理类,我们需要自己提供这样的设施。例如Font管理FontHandle资源,但我们不能直接把Font传递给接受FontHandle的api。
1 | // resource class |
一种(显式)做法是为Font添加一个get()函数,用户显式调用get()来获得FontHandle对象:
1 | class Font { |
另一种(隐式)做法是允许Font到FontHandle的类型转换:
1 | class Font { |
这样可以让用户直接将Font提供给接受FontHandle的函数,代价是会发生误用,比如:
1 | Font f1(getFont()); |
这样的代码可以通过编译,使f2指向一个f1管理的内部对象,导致潜在的问题。
Item 16: Use the same form in corresponding uses of new and delete
使用new和delete的时候必须配对,new[]生成的对象需要用delete []操作符释放。
1 | std::string *sp1 = new std::string; |
这样的错误在使用typedef时容易出现:
1 | typedef std::string AddressLines[4]; |
尽量避免typedef出一个数组,可以使用std::vector或者std::array。
Item 17: Store newed objects in smart pointers in standalone statements
由于C++没有规定函数参数的求值顺序,可能出现这样的问题:
1 | processWidget(std::shared_ptr<Widget>(new Widget), priority()); |
priority()的调用可能发生在new Widget和std::shared_ptr<widget>()之间,破坏了RAII,因为这个函数可能抛异常。
最好在单独的语句里把new出来的对象赋给智能指针:
1 | std::shared_ptr<Widget> pw(new Widget); |
Designs and Declarations
Item 18: Make interfaces easy to use correctly and hard to use incorrectly
本节讨论了一些设计接口的例子,目的是让用户错误使用接口时触发编译错误。
例1:一个日期类,它不能处理用户的错误使用:
1 | class Date { |
可以把年月日从int变成wrapper
type,并添加校验防止非法值。
1 | struct Day { |
例2:加减乘除等运算符返回这样做不合理,见Item3。const引用,防止类似if (a + b = c)这样的错误。
例3:Factory类与其返回裸指针,不如返回智能指针防止用户忘记free。
Item 19: Treat class design as type design
本节指出了一些定义class的方法论,不列举了。
Item 20: Prefer pass-by-reference-to-const to pass-by-value
如果一个函数不需要修改某个作为参数传进来的对象Object,它最好接受一个const Objct&(常引用),而不是Object(直接传值),因为:
没有拷贝构造和析构的开销
直接传值触发不了动态绑定,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class A {
public:
virtual void foo() const {cout << "A::foo()" << endl;}
};
class B : public A {
public:
void foo() const {cout << "B::foo()" << endl;}
};
void bar1(A obj) {
obj.foo();
}
void bar2(const A& obj) {
obj.foo();
}
int main() {
B b;
bar1(b); // A::foo()
bar2(b); // B::foo()
}
作者认为应该传值而非传引用的例外:
- 内置类型。因为传引用(大概率,和实现有关)相当于传指针(8字节),对于内置类型还是直接传值快一点。
- 迭代器和函数对象,这些类比较小,设计上就是希望当值传递。
作者认为,即使一个class并不大,也不能成为传值而非传引用的理由,因为:
- class不大不意味着拷贝构造函数简单。例如
std::vector包含一个指针和一些元数据,但深拷贝需要把里面存着的元素全拷贝一遍。 - class的实现可能变化,现在不大以后可能会大。
Item 21: Don't try to return a reference when you must return an object
假设我们有一个有理数Rational,我们为它重载了友元函数,将两个Rational相乘:
1 | class Rational { |
友元在类里只进行声明,无论声明位置访问权限如何(比如这里的private)都不影响友元本身的访问权限。
这里operator *返回了一个值,能不能让它返回引用以减少拷贝呢?如果可以,这就必须在operator*内部创建一个新的Rational对象,否则Rational z = x * y的用法就不成立。
- 如果在栈上创建,函数返回时该对象就会被销毁。
- 如果在堆上创建,调用者需要负责回收这个对象。这显然是不合理的,因为在
Rational w = x * y * z这样的用法中,调用者无法回收中间的临时结果。
事实上,这种情况下就应该返回值,无法返回引用。编译器可能会做返回值优化,这是另一码事。
Item 22: Declare data members private
类的成员变量应该被声明为private,因为:
- 所有变量都通过getter/setter读写,具有一致性(牵强)
- 可以通过提供不同的getter/setter控制变量的读/写权限
- 封装,使用者不关心实现
作者还认为,声明protected成员变量提供的封装性和public半斤八两,无非前者只会让派生类使用罢了。一旦一个public/protected成员变量被移除,都会涉及外部代码的更改,只是改多改少的问题。
Item 23: Prefer non-member non-friend functions to member functions
假设有一个WebBrowser类,暴露出了如下接口。如果我们还想提供一个接口用于一次性执行这3个动作,可以:
- 增加一个成员函数
- 在类外增加一个util函数,这个函数既不是成员函数也不是友元函数,即只能访问
WebBrowser的public部分。
1 | class WebBrowser { |
作者认为,选择2更能保证类的封装性(主要好处),同时能降低不同源代码之间的编译依赖度(次要好处),论证如下:
能够访问某成员变量的函数越多,这个成员变量被封装得就越差。做法1引入了一个额外的public函数,它能touch到类中的private成员,降低了类及其成员变量的封装性。
对于这种场景,best practice是定义一个围绕
WebBrowser的命名空间WebBrowserStuff,把clearBrowser()这样的聚合函数分类放在不同的头文件里,即:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// webbrowser.h
// class WebBrowser itself and coreutils of webbrowser
namespace WebBrowserStuff {
class WebBrowser {...};
void clearBrowser();
...
}
// webbrowserbookmark.h
// functions related to bookmark management
namespace WebBrowserStuff {
...
}
// webbrowsercookie.h
// functions related to cookie management
namespace WebBrowserStuff {
...
}这正是标准库
std的组织方式,用户可以根据需要的功能包含不同的头文件,降低编译依赖度(即不需要拉一堆用不到的函数进来编译)。class的定义是不能被拆到多个头文件中的,因此只有使用non-member & non-friend函数才能达到这个目的。
Item 24: Declare non-member functions when type conversions should apply to all parameters
如果有一个有理数类Rational,重载了operator*如下:
1 | class Rational { |
显然,两个Rational的乘法没有任何问题。由于我们构造函数的定义,int变量可以被隐式转换为Rational。但是,Rational和int的乘法不满足交换律:
1 | int main() { |
2和a相乘时,2可能位于乘号的左边或右边,都应该保证它正常发生隐式类型转换。此时应该把operator *定义成非成员函数。
1 | Rational operator*(const Rational &rhs, const Rational &lhs){ |
Item 25: Consider support for a non-throwing swap
本节的逻辑比较复杂,以下内容均针对pre-C++11。
Motivation
std::swap的是通过创建一个临时变量和两次拷贝构造实现的,这对于C++中广泛存在的pimpl
(Pointer to implementation) idiom并不友好,因为一个类的定义可能是:
1 | class Widget { |
要交换两个Widget,其实只需要交换它们各自的pImpl即可。但默认的std::swap实现会拷贝WidgetImpl。
显然,我们需要针对Widget类实现特定版本的swap。
Challenge
我们不可能修改标准库,怎么让用户能调用到自己的
swap?答:事实上,
std::swap被定义为一个函数模板。1
2
3
4
5
6
7
8
9namespace std{
template<typename T>
void swap(T& a, T& b)
{
T temp(a);
a = b;
b = temp;
}
}如果我们提供一个更特化的版本,它会被编译器优先匹配到。
pImpl是Widget的private变量,即使实现了特化的swap,它也无法交换pImpl指针。答:所以类的内部需要实现一个
swap成员函数用于交换pImpl。
Design
因此,我们首先实现一个swap成员函数:
1 | class Widget { |
然后为Widget特化std::swap,这里是一个total
template
specialization,因为template<>里面已经没有模板参数T了:
1 | namespace std { |
在本例中,这样做就可以了。但是,如果Widget本身不是一个class,而是一个class
template,会带来新的问题:
1 | template<typename T> |
这里特化后的swap仍然有模板参数T,尽管它原来接受任何T,现在只接受Widget<T>。鉴于template<T>里面仍然存在模板参数,这里只是一个对swap的偏特化(partially
specialize)而非全特化,而对函数模板的偏特化是C++不允许的。
因此,我们使用函数重载来替代全特化:
1 | namespace std { |
这里的swap后面没有尖括号,因此不是偏特化,而是一个与std::swap拥有不同签名的函数重载。
然而,标准不允许我们在std命名空间内添加函数重载,我们最好把这个重载移出std。我们当然可以把它定义在global作用域下,但一个更好的选择是为Widget创建一个专属的命名空间,以避免混乱:
1 | namespace WidgetStuff { |
这样一来,用户就可以使用Widget自定义的swap版本了,用法是:
1 | template<typename T> |
通过using std::swap,编译器会在typeof(obj1)的类型没有自定义swap的时候,匹配到std::swap这一通用版本。当typeof(obj1)存在自定义swap的时候,编译器基于Argument-dependent
lookup在参数的命名空间中找到并调用了WidgetStuff::swap,符合我们的预期。
Appendix
看起来,在专属命名空间中添加一个non-member的swap版本不仅适用于Widget是普通类的情况,也适用于Widget是类模板的情况,我们也不需要再特化std::swap了。但作者仍然建议我们这么做(当然只是在Widget是普通类的前提下,否则编译都过不了),因为用户可能会不正确地使用swap,即:
1 | template<typename T> |
用户错误地直接指定要使用std命名空间中的swap,如果我们也特化了std::swap,这一错误用法的结果仍然是正确的,可以调用到效率更高的自定义swap。特化std::swap相当于给用户的错误行为做了兜底。
Conclusion
当我们不想使用std::swap的默认实现时(基于拷贝),需要为自己的类C实现swap,步骤是:
- 实现一个
swap成员函数,它高效交换两个C类型对象,且不能抛异常。 - 在
C的命名空间中实现一个non-member swap,调用上述成员函数。 - 如果
C是一个类(而非一个类模板),在std中特化一个swap,令其调用上述成员函数。
回到本节的标题,为什么要支持一个noexcept的swap呢?因为swap被用于实现copy-and-swap
idiom,前提条件就是不能抛异常,而默认的std::swap做不到这一点。
最后,本节的内容在C++11之后是部分过时的,因为std::swap已经基于移动语义实现了。当然,如果你不希望发生一次移动构造和两次移动赋值,或者希望拥有一个noexcept的swap以用于copy-and-swap
idiom,仍然可以按照本节内容实现一个自定义的swap。